

Large swaths of personal data is routinely stolen from companies and governments with alarming frequency. It seems like these organizations simply have no clue how insecurely their data is stored, and even less of a clue how to prevent data theft. With few exceptions, these data thefts are made possible by poor code, poor configuration management, poor training, or a combination of all three. In this article we’ll draw attention to some general concepts that developers and system administrators should pay attention to in order to secure their systems.
Useful terminology
Attack vector
The “direction” of an attack. Common attack vectors are phishing emails, remote code exploits launched from the internet, and denial of service attacks that take down web services.
Attack surface
A generic term that refers to the variety of ways in which a system can be attacked. The goal is to have a small attack surface; systems with many vulnerabilities are said to have a wide, or large, attack surface.
Exploit
The actual attack used to take advantage of a vulnerability. For example, the Wanna Cry ransomware attack used an exploit named EternalBlue that targeted a vulnerability in MS Windows Server Message Block (SMB) protocol.
Heap
The pool of available memory in a computer’s memory that can be allocated to programs. Memory is doled out from the heap by the operating system as requested and programs return it when they’re done.
Patch
A small piece of code that fixes a very specific part of a program. If a program is found to have a vulnerability, there is usually no need to replace the entire program. Rather, the vendor can just rewrite the bits of code that need it and then issue a patch file. A patch file is automatically injected into the existing program and is said to “patch” the hole.
Vulnerability
The weakness in the system that is being targeted by the exploit. Using the Wanna Cry ransomware attack example again, the vulnerability was in how the Windows Server Message Block handled some requests.
Zero day (0-day)
A vulnerability that has been discovered and not fixed yet. When bad guys discover a vulnerability, they generally don’t tell the program vendor. They write an exploit for it and start attacking systems that have the vulnerability. Eventually, the good guys notice this or discover the vulnerability on their own and at that point the vendor is usually notified. The time period between the vulnerability being discovered and the vendor being notified of it is the zero day period. It is usually much longer than a day.
Program code
Programs are written by people and people are fallible. Therefore many programs in use today have vulnerabilities. The list of how vulnerabilities can be introduced into code is almost inexhaustible, but the most common ones involve being too trusting of input from the user.
Failure to sanitize input
Developers use test routines to validate that the code does what it is intended to do. In most cases, the tests are focussed on whether the code does what it should because that is easy to build test cases around. If a piece of code is supposed to add two numbers together, then a test case would be to feed it two numbers and make sure it gives the correct result. This works fine since the input is correct: it is two numbers which is what the code expects.
It’s less easy to test code to see what it does when it doesn’t get the input it expects. What happens if the code is fed two letters, or only one number, or a bunch of special characters like <*`?
While it’s easy to generate good test input (two numbers), it’s very difficult to figure out all the possible combinations of bad input. Therefore, programmers should assume that their code will be fed bad input from an untrusted source. Instead of trying to guess what the input might be, code should just gracefully refuse to accept data that is not in the format it expects. The exercise of cleaning up code is called input sanitization.
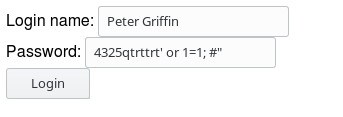
In the image above, I’ve set up the a very dumb login page. My code assumes that the user will enter their username and password and it makes no attempt to determine if the input looks valid before sending it as a query to my user database. Instead of a password, I’ve entered a SQL string that will dump my entire user database complete with passwords to the browser. The resulting query and result looks like this after I click the Login button:
 I’ve now given away all my customer’s passwords. Had I sanitized the input and removed the special characters before processing it, this would not have been possible.
I’ve now given away all my customer’s passwords. Had I sanitized the input and removed the special characters before processing it, this would not have been possible.
Failure to test boundaries
The operating system is in charge of allocating memory to programs. Computer memory is a very dynamic place with data being written and read from memory constantly and some of that data is sensitive. When an application is running, it may store credentials like usernames and passwords in memory, or authentication keys needed to access other systems. The program keeps track of where that data is stored so it can retrieve it when necessary. That works fine as long as a program only reads its own data. If it reads or writes more data than can fit in the memory space it’s been allocated, that’s an overflow.
The simplest way to explain an overflow issue is to envision a program asking the operating system for 1 byte of memory from the heap in order to write some data. The operating system allocates that 1 byte and tells the program the memory address where that byte begins. The program then writes some data to that space. Next, the program requests data from the start of the memory it was allocated, but it asks for 2 bytes of information instead of just the 1 byte it has been allocated. In that way, the program has now managed to get 1 byte of information that doesn’t belong to it, and may contain sensitive information.
In addition to attempting to read data from unallocated memory, attackers can also use memory overflow attacks to simply crash a program. If an important program, such as a software firewall, can be made to crash by another program overwriting its memory space, that can leave the firewall down and the system exposed. Sometimes, an attack like this doesn’t care what it can read or write to memory, it just wants to change the memory in some way hoping to weaken the system overall.
A program should test the boundaries of any data it uses before processing it to avoid this type of overflow problem.
Repeating chunks of code
There are many names for this concept, but they all refer to the same thing: programming functions. Every mature programming language has some concept of splitting code into functions. This allows programmers to break down complex code into smaller chunks that are easier to deal with. Taking the example of our calculating code that adds two numbers together, it could be broken down into a few different functions like so:
- Function that takes input from the user
- Function that sanitizes that input to make sure it is two digits
- Function that adds the two numbers together
- Function that prints the result to the screen
If the programs has bugs or needs to be modified, it’s easier to do that when the code is broken into discrete functions like this. For example, if the program is to be modified to also support multiplication, then only two things needs to happen:
- Modify the first function to determine if it has been asked to add or multiply the two numbers
- Add a function to do the multiplication
Note that three of the functions do not need to be touched in order to add this modification. The program can still sanitize the input and print the results to the screen without any changes to that code. This means fewer opportunities to introduce bugs or vulnerabilities than if the entire code base had to be modified.
Developers should encapsulate discrete bits of functionality as much as practical.
Leaving test code in production
Writing code is a lot like writing an article. It’s an iterative process where broad strokes are used in the beginning to get a structure laid out, and then subsequent development cycles fill in the code to eventually produce a working program.
During earlier cycles, programming functions are usually defined, but “stubbed out”. This means the functions don’t actually do anything yet, they just return test values. Those test values can be used to validate other parts of the program before writing each actual function. In complicated programs, test code can sometimes be forgotten about and end up in production. Depending on what the test code does, it could introduce serious vulnerabilities into the production system.
Code review and audits should be a standard part of the development process for any application.
System configuration
Even good software can be configured poorly. One of the most common configuration errors is to not configure an application at all.
Default username and passwords
A very obvious example of the problem with default credentials was the crippling Mirai botnet DDoS attack in October 2016. The botnet used in that attack was comprised almost entirely of internet-connected closed-circuit cameras that people had bought, set up, connected to the internet, and never changed the default password. The Mirai software was able to take over millions of these cameras simply by logging in over the internet with the default credentials.
It is important for new hardware to be introduced into the company properly. All new hardware should come through the IT department and part of the onboarding process should be to change the default credentials.
Installing from Linux package managers
Each major strain of Linux comes with its own package manager. The two most common package managers are the Redhat Package Manager (RPM) and the Debian-based Advanced Package Tool (APT). Software can be installed, upgraded, and removed using these package managers.
While it’s very convenient to use these package managers, the software in those repositories is frequently not the most current. Running out of date software can be just as dangerous as running unpatched software. Rootkit hunter, for example, is at version 1.4.4 but only 1.4.2.5 is available in the Ubuntu repositories.

There may be legitimate reasons to run non-current software, but system administrators should not rely on distribution software repositories being up to date.
Resource starvation
This is a joint developer and systems administrator issue. Programs need memory, disk space, and CPU cycles in order to operate. Computers have finite amounts of these resources and they are shared with all the other programs on the computer, including the operating system.
It’s important to test what a program will do if it suddenly runs out of memory, or can’t write data to the disk any more. Poorly coded programs may display memory dumps which can contain sensitive data, or they may write core files to a directory an attacker can access. Another consideration is what happens when the program is no longer running. If it’s a web server, then the website will go down. If it’s an authentication program processing thousands of logins a minute, that’s another type of problem.
Developers should understand how much memory and disk space their program is likely to need, and write their code to gracefully fail if it runs out of resources. System administrators should also understand how much memory and disk space the programs on any given system require in order to properly provision the servers.
Patch management
An increasingly common attack vector is unpatched software. Recall the definition of a zero-day exploit – that is an exploit that targets a vulnerability in an application that the vendor is not aware of yet. Eventually, the vendor will patch that vulnerability and everyone using that application then upgrades to close that vulnerability on their system.
That’s how it is supposed to work. In reality a very large number of systems are not patched properly due to mismanagement or inexperience.
If a vulnerability can be exploited as long as it remains a “zero-day”, then what happens on “day one” – the day after it the vendor announces the patch is available?
The bad guys download the patch and analyze it to see what is being changed. In some cases, they can find out what was changed and derive what the vulnerability is from those changes. They then go searching for systems that have not been patched yet knowing that they will be able to exploit them. For this reason, responsible vulnerability disclosure usually follows this path:
- Good guy discovers vulnerability: Somehow. Maybe the good guys just stumbles across the attack during routine log analysis, or maybe the good guy is a security researcher that discovered the vulnerability.
- Vendor is notified: Many vendors have vulnerability reporting systems. In general, a vulnerability report is accompanied by a proof-of-concept to show the vendor the details.
- Vendor patches vulnerability and pushes it out: It’s at this time the vendors customers would be notified that there is an update available for their system. Some users, such as Windows users, will receive the updates in a routine monthly update. Most users will have to update their system themselves.
- Disclosure is made: Note that the vendor normally will not disclose the vulnerability that has been mitigated until their customer base has had time to apply the patch. This delay period can be a few hours or a few days. The security research industry is driven by reputation, so the person or group that discovered the vulnerability will usually disclose it publicly in coordination with the vendor.
The recent Wanna Cry ransom attack is an example of how bad zero-day exploits are. The accepted series of events that led to the Wanna Cry attack is this: The hacker group The Shadow Brokers stole the exploit from the NSA and dumped it on the internet after unsuccessful attempts to auction it off. Bad guys then used that exploit to launch the attack. The underlying vulnerability is in Windows Server Message Block (SMB) version 1, which is very old. It’s not entirely clear when the NSA discovered the vulnerability but since they developed a specific exploit for it, named EternalBlue, it seems it had been exploiting it for some time. That vulnerability was a zero-day exploit for months or years with only the NSA knowing about its existence.
Following this process, it becomes obvious why patches and updates need to be applied to production systems as soon as possible. Microsoft patched EternalBlue in March 2017, two months before the Wanna Cry outbreak, so properly patched system were not affected.
It’s understandable that rushing a vendor patch into production contains its own set of risks. Responsible patch management will include a system to test patches in a Quality Assurance (QA) environment with the aim to push them into production as soon as possible.
The best defence against exploits is to use best practices and keep your systems updated.
Best practices include:
Reuse code: don’t write your own sanitization routines if your programming library already has one. In most cases, heavily reviewed and well-used code has been debugged by thousands of eyes and will work better than anything you’re likely to whip up in isolation.
Keep system updated: it’s surprising how many large, well-publicized hacks can be traced back to neglected systems that were running out of date, or unpatched, software.
Stay informed: system administrators and developers should subscribe to the security alerts of every product on their systems. In addition, keeping an eye on the Common Vulnerability and Exposure website can help.
Defend against skill fade: IT is a broad field and most of us spend our careers leaping from area to area. After spending a long time one area, say database administration, any web server skills you had will probably start to fade. Attackers spend all their time in one space and become extremely skilled. It’s important to ensure your skills remain current to defend against them.

{kind=link}