
 attacks?){kind=link}

Cross-site request forgery (CSRF) attacks can be difficult to wrap your head around. There can be a lot of variation in these attacks, so it can be hard to see what truly lies at their core.
In short, cross-site request forgeries involve attackers tricking your web browser into sending their forged requests to the server. Because these requests seem to come from your browser and include your authentication data, the website thinks that they are legitimate.
The server complies with the request, which could be to change your password, change the email associated with your account, or even steal money from your bank account. This can all happen without you clicking on anything, and even without your knowledge. Ultimately, CSRF attacks can have devastating consequences, as they can grant attackers complete control of accounts.
Cross-site request forgery attacks are also known as hostile linking or session riding. The CSRF acronym is often pronounced sea-surf, and the C is occasionally replaced by an X to form XSRF.
If you are completely stumped about these attacks, or have a rough idea, but don’t completely understand how they work, don’t worry. We’re going to introduce each of the key concepts slowly and in detail, so that by the end of the article you should have a solid grasp of what cross-site request forgery attacks really are.
Feel free to skip over any parts you are already familiar with–not everyone has the same background knowledge, and it’s better to cover more than is necessary for some people, rather than under-explain key concepts, and then have you frantically searching the web to answer your questions.
What are Cross-site request forgery attacks?
Let’s start by breaking down the name. In this case, it’s actually quite illustrative of what these attacks are at their core. On one hand, we have “cross-site”, which alludes to the fact that the attack originates from one site, but acts on another.
The other element is “request forgery”. This is pretty obvious – these attacks somehow involve someone forging requests. So when we bring these two concepts together, we have attackers forging requests that originate on one site, but act on another.
Cross-site request forgeries (CSRF) and state changes
One of the first things you need to wrap your head around is that cross-site request forgeries involve changing the state of data on a website’s server. This simply means that the attacker sends a request to modify the data on the server on the victim’s behalf. If the request is accepted, the data is changed.
This is because CSRF attacks don’t give hackers any visibility into the server’s response to the victim. Forging requests that asked for sensitive data would be pointless, because the sensitive data would be sent to the victim, not the attacker.
While CSRF attacks don’t allow hackers to directly steal data, changing the state of data on a server can still be a powerful move that causes significant harm to the victim. An attacker could forge a request that gets sent through the victim’s browser, asking the server to send funds from the victim’s account into one controlled by the attacker.
In this case, the request is to change the state of the victim’s bank balance. If it is accepted by the server, the attacker can make off with the victim’s money. Even though the server never sends any information to the attacker’s computer, the request tricks the bank into sending money into the attacker’s account.
Similarly, attackers can send forged requests through the victim’s browser that ask to change the victim’s password to something the attacker knows. If the server accepts the request, it makes it easy for the attacker to take over the victim’s account once the password has been switched.
Attackers can achieve the same outcome if they forge a request to change the email address on the victim’s account to one that the attacker owns. They can then ask the site to reset the password, and the authentication email will go straight to the attacker rather than to the account owner. From this point, they change the password, and the account is in their hands.
While the cross-site request forgeries in these attacks don’t directly involve the website sending user data to the attacker, these latter two examples make it easy for the attacker to steal data once they are in control of the account. They show just how devastating changing the state of data on the server can be.
The necessary conditions for cross-site request forgery (CSRF) attacks
Cross-site request forgeries require a range of conditions to be met in order for these attacks to be viable options. These include:
They need to target websites where users can request changes to the state of data on the server
CSRF attacks are used to circumvent the authorization and authentication processes that are normally in place. This means that these attacks are pointless on static websites and sites where there are no user accounts that can make requests to change the state of data on the server.
Attackers will only bother with CSRF attacks if these server state changes can actually benefit them, such as if they can make funds transfers, or take over accounts that have valuable access or information.
Victims need to be logged in at the time of the attack
Many websites use session cookies with unique identifiers to grant users access to authorized pages. These are generated when victims first log in and only last for the session, which means that victims need to be logged in at the time the forged request is sent in order for CSRF attacks to succeed.
When they are logged in, attackers can trick the browsers of their victims into sending requests that the user did not intend to make. These malicious requests are accepted by the server because they include the victim’s session cookie, which makes them seem legitimate to the server.
The majority of cross-site request forgery attacks involve taking advantage of session cookie authentication, however, some less-common authentication systems can also be compromised through CSRF attacks.
Victims must visit the page that hosts the forged request
The attacker needs to find a way to make victims visit a specific page that hosts the forged request. This can be relatively easy in the case of stored cross-site request forgeries, which we will discuss later. Otherwise, it may require luring victims to a separate website, and tricking them into clicking a link or having the malicious request triggered automatically via scripts.
The website needs predictable parameters
In order to forge a request that will actually be accepted by the server, the attacker needs to know what these requests are supposed to look like. Let’s explain why this is important with an analogy.
If you wanted to forge a check and cash it in at the bank, you would first need to know how to properly write a check. If you had written the name in the box for the date, the account number as the amount, and made a whole bunch of other screw-ups, the bank would simply reject your forged check, and you would never get the money you desired.
It’s similar if an attacker wants to be able to change the state of the server’s data in their favor. They need to know how the website typically formats requests if you want to be able to forge a request that will actually get accepted. If an attacker tried to change the password for an account, but the values were incorrect or in the wrong order, the request would be rejected, and they would have wasted their time.
This means that for CSRF attacks to succeed, the website needs to have predictable parameters. If every request follows the same predictable format, an attacker can examine previous requests and abuse this knowledge to forge a request that’s actually in the correct format. If the request requires passwords, IDs, or secret authentication values that the attacker cannot guess, they will be unable to successfully perform a cross-site request forgery attack.
Back to basics: Understanding the security ecosystem that CSRF attacks circumvent
Now that we have covered the basic conditions necessary for cross-site request forgery attacks, it’s a good opportunity to take a step back and examine the important elements of the security landscape that these attacks attempt to get around. It can be hard to truly understand why attackers turn to CSRF attacks if you aren’t familiar with the systems that are already in place.
Accounts
Unless you are Amish or a Luddite, you probably have a bunch of different accounts for the various web services you use. You presumably have accounts for your email, social media, banking and much more.
But why do you have these accounts in the first place?
Because you often do important things on these websites. For an online banking website to actually be useful, it needs to allow you to check your balance, send new transfers and perform a range of other actions. You may also need to change your password at times, and update your personal details.
While it’s essential that websites allow you to do each of these tasks, it’s critical for the sites to only allow you to do them. If anyone could use the banking website to send your money to themselves, or change your password, the chaos this would result in would be far more detrimental than the benefits the service offers.
Accounts help to control the information and systems that you are allowed to access. If an email provider simply had an honor system and stored all email in a database that everyone could access, no one could be granted any privacy in their communications.
When we are dealing with important information, it’s often best to have user accounts that limit what each individual can access. This is especially important when privacy is crucial, or if someone else’s changes could have negative effects.
As an example of where user accounts make sense, most of us don’t have Wikipedia accounts, because most people aren’t Wikipedia editors. However, we can all still visit the website and learn about whatever interests us. There isn’t too much damage you can do by simply visiting and reading the site.
However, if Wikipedia didn’t require accounts for its editors, the website would quickly deteriorate. Editors can create and alter the information, so there need to be protections in place that stop people from defacing the site and writing gibberish. While Wikipedia doesn’t always succeed in preventing these outcomes, it would be a lot worse if there were no control mechanisms in place.
Authorization and authentication
So know we know why we need user accounts. But we also require systems in place that control the information and resources that each user is authorized to access. We need ways to authenticate each user as well. We need to be able to determine that people are who they say that they are, and aren’t just impostors.
Once again, you wouldn’t be too satisfied if your online banking website just had an honor system in place. What would prevent hackers from simply saying that they are you, and then sifting through your data they aren’t supposed to access? What would stop them from going into your account and sending all of your money to themselves?
Instead of this ludicrous free-for-all, we have authentication systems like usernames, passwords, and two-factor authentication that restrict people so that they can only access the resources they are authorized to access. As long as you have a strong password, you keep the password a secret, and you protect your second authentication factor (ideally an authentication app or a security token, because SMS authentication isn’t that safe), it’s pretty hard for an attacker to pretend that they are really you.
In most cases (these systems aren’t foolproof, but good enough for most purposes when implemented and used properly), if a website has appropriate protective measures in place and you take your security responsibilities seriously, you can be relatively confident that it would be a significant challenge for an attacker to impersonate you. This difficulty keeps your account balance from being drained, your emails from being read, and strangers from posting crazy rants on your social media.
In a simplified system that was designed to protect your data, you may be expected to prove your identity and authenticate yourself by logging in every time you visit a new page within a website. You would log in once to get to your account overview page. If you wanted to check a transaction from two months ago, you would probably have to visit a new page and log in all over again. If you wanted to make a new funds transfer, you would have to log in once more.
Obviously, this would quickly become tedious and make the internet far less usable. Thankfully, developers have come up with systems to prevent you from having to do this for each and every page. The most common technique involves session cookies.
Session cookies
When you successfully log in to an account by authenticating yourself with the correct username and password, most website servers will insert a session cookie into your browser. The session cookie includes a unique session identification number, and the server stores its own copy of this ID. These session IDs are complicated enough that it’s unfeasible for an attacker to simply guess them. They also expire at the end of each session, so the next time you log in, a new session ID will be planted in your browser.
The benefit of session cookies is that instead of being forced to prove your identity by logging in each time you visit a new page. Instead, the website’s server will simply look for the session ID in the cookie it planted when you logged in.
Whenever you click to visit a new page within the website, your browser will send a request to the website’s server. Each of these requests includes the cookie with your session ID. The server receives the request along with the cookie and compares the session ID along with the value it stored when the session was created. If the two match, it assumes that it is the correct user, and grants you access to the resources you are authorized to access.
With the session ID stored in the cookie in your browser, you can make your way across the website’s pages and perform a variety of actions, like changing your password, updating your email address, and setting up new funds transfers. With this cookie-based authentication system in place, you don’t have to log in separately for each task.
While this system generally works quite well, it’s also what cross-site request forgeries try to take advantage of if the right precautions aren’t in place.
In cases where the unique session ID is the only thing necessary to prove your identity once you have already logged in, it follows that if the attacker can figure out how to manipulate this ID without your knowledge, they could use it to perform some of the actions that only you have the authorization to perform. They may be able to transfer your money, change your password or the email address that is registered with your account, or commit a range of other attacks.
HTTP requests
Now that we’ve covered the absolute basics of how your accounts and the information within them is secured, we can look into how data is actually transferred between clients and servers over HTTP.
HTTP is one of the web’s most important protocols. When you visit a website, your web browser– the client–sends a HTTP request to the website’s server. The server receives the request, then generally sends you back the resources you asked for in its response, or it makes the changes you requested.
In the case of visiting Comparitech.com, your browser would start by finding the site’s server. Then it would send the server a HTTP request asking it to send a copy of Comparitech’s home page. If the server approved the request, it would send you a copy of our home page via a series of data packets. Your browser would collect these packets, then use them to show you a copy of our website. You could then peruse our content at your leisure.
If you then clicked on one of our articles, such as the one you are currently reading, your browser would send another HTTP request to the server. The server would usually approve it, then send you the copy in a large number of data packets. Your browser would then assemble the data into this article for you to read.
If you were browsing the internet in a relatively normal fashion, the servers you make requests to will tend to approve the majority of your requests. However, there are also a number of reasons for them to deny requests. Servers may not be able to locate the resource you are trying to access and return an error message in response to your request.
In another case, a request may not include the necessary authentication information to access a specific resource. In this case, the server will deny the request. One example of how this could happen is if an attacker tried to access your bank account, without the correct session ID that indicates they actually have authorization.
Cross-site request forgery attacks are conducted with forged HTTP requests. In order to succeed in their attacks, hackers need to figure out ways for their forged requests to be accepted by the server.
The different types of HTTP request
There are a variety of HTTP requests which perform separate functions. They include:
GET requests
This type of request is used to request resources from a website’s server. In our earlier example of you visiting the Comparitech.com website, your browser’s request to our server was a GET request. This is because you were asking the server for data.
When implemented correctly, GET requests should only retrieve data. Despite this, sometimes poor implementations will allow them to change the state of data. As you will see in our GET requests in CSRF section, this can cause security issues.
One of the reasons for this is that GET requests are logged by servers, stored in the browser history, can be cached, and can also be bookmarked. This makes them unsuitable for sending sensitive data.
POST requests
Post requests are used to submit data to servers and can change the state of the data they store. The content of these requests is sent in the body, they are never cached, can’t be bookmarked and don’t remain in the browser history. This makes them more appropriate for sending sensitive or valuable data.
A good example of a POST request that you will be familiar with occurs when you fill out website submission fields, such as contact forms. When you click the submit button, the data you entered into the input fields is sent as a POST request.
Other types of HTTP requests
- PUT requests – This type of request either replaces an existing resource or creates a new one if it didn’t already exist.
- DELETE requests – A DELETE request will delete the specified resource.
- HEAD requests – These requests ask the server for the metadata for a specific resource. It’s important to note that these requests don’t also seek the body data as GET requests do. HEAD requests can be used for things like finding out when a resource was updated.
There are also TRACE, PATCH, OPTIONS and CONNECT requests. We won’t cover them here, but if you are curious, you can learn about them in this article from Mozilla.
GET and POST requests are the most common in CSRF attacks, so we will give you examples of how each of these attacks work.
POST requests in CSRF
We will begin with an example of how POST requests can be manipulated to compromise a victim’s account. As we mentioned, POST requests are used to submit data in online forms. Let’s say yourfavoritewebsite.com uses a form for you to change your password. Of course, this is a necessary feature, because it’s important for people to be able to change their passwords if they suspect that their account may be compromised.
Forging the request form
The input fields for the password change could look something like this in HTML:
<form action=”#” method=”POST”> New password:<br>
<input type=”password” AUTOCOMPLETE=”off” name=”password_new”><br>
Confirm new password: <br>
<input type=”password” AUTOCOMPLETE=”off” name=”password_conf”>
<br>
<input type=”submit” value=”Change” name=”Change”>
</form>
Note where it says method=“POST” which tells us that this is a POST request. POST requests are important for sensitive data like passwords because they send the data as part of the body, which isn’t logged or saved in the browser. This helps to keep new passwords confidential.
If you look to the left, you will see that it features the attribute action= “#”. This specifies the target of the request. The hash symbol is a placeholder.
You will also notice that the form frequently says name=. This attribute contains the name of the parameter for the data you will submit. In this example name=”password_new” and name=”password_conf” align with where the form would say New password and Confirm new password, respectively. If you enter password123 in both fields, it will be set as the new value for the name=”password_new” and name=”password_conf” parameters.
When you submit the form, your browser will send a POST request that includes the following headers, among others:
- HOST: yourfavoritewebsite.com
- Cookie: SESSION=872e98c2dab1974e75
The second header is the unique session ID that was created when you logged into the website.
Everything we’ve shown above is relatively normal and necessary for allowing users to change their passwords when needed.
Let’s imagine that an attacker visits the website from their own account, goes to the page to change their password, right-clicks anywhere on the page, then clicks on Inspect in the menu that pops up. This will bring up the underlying code for any page–you can try it for yourself on any web page.
Doing this on the page for changing passwords, can easily grant the attacker access to the form’s code. They could then copy it and make their own modifications, in order to forge a request that changes the victim’s password.
The attacker would add in the necessary elements to make the form function properly, such as the HTML tags, head and body. They would also write some JavaScript to make the form submit automatically so that the attack could proceed without the user having to purposely send through the form. This makes the attack even more likely to succeed.
In addition to this new code, the attacker would add in the page’s address as the target for the action attribute. They would also add in new values for name=”password_new” and name=”password_conf”. The attacker would set these values to whatever they want the new password to be.
The only thing that matters is that the password is something that they know. In this case, “csrfattack” is entered into both input fields as the new password. The key parts might look something like the following:
<form name=”Form” action=”yourfavoritewebsite.com/changepassword” method=”POST”> New password:<br>
<input type=”hidden” AUTOCOMPLETE=”off” name=”password_new” value=”csrfattack”><br>
Confirm new password: <br>
<input type=”hidden” AUTOCOMPLETE=”off” name=”password_conf” value=”csrfattack”>
<br>
<input type=”submit” value=”Change” name=”Change”>
</form>
With the above form, the attacker has forged a POST request to change the victim’s password. The next step is to figure out a way to trick the user into sending it. If the attacker can do this, then they will be able to change the victim’s password to one that they know, allowing them to take over the account. From this point, they would be able to do whatever the victim is authorized to do with the account.
Setting up the attack
However, as we discussed previously, there are security mechanisms in place to protect the user’s account. The form to change the password for a user account cannot be accessed unless the user is logged in. When the user logs in, the server creates a unique and hard-to-guess user ID for the session. This session ID is used to grant the user access to authorized resources as they move from page to page, performing different actions on the website.
The server keeps a copy of this unique session ID, while the user’s browser stores it in a cookie in their browser. The session ID is required to successfully change the user’s password.
If the attacker wants to send a request that successfully changes the victim’s password, the user needs to be logged in, and somehow the attacker needs to get the session cookie sent to the website alongside their malicious request. At first, these may seem like two pretty big challenges.
In practice, the first one often isn’t too difficult. Many people are almost always logged into some of their accounts. If this isn’t the case, the attacker could just hope that the victim is logged in at the time they come across the malicious request, or find some way to manipulate them into entering their account.
Presuming that the attacker can perform the attack at the same time that the victim is logged in, the next step is to host the malicious form they have created somewhere. Let’s say they place it at evilwebsite.com/attack.html, which the attacker controls. Now, all that the attacker has to do is trick the victim into visiting this website with the malicious form.
As we said above, the attacker will have written some JavaScript to make the form submit automatically. This means that once the victim visits the site, they won’t even have to click on anything – the forged request to change their password will send itself.
There are many ways to trick people into visiting a website that initiates a CSRF attack, but we will cover them in more detail in the Luring in victims section further down in the article. One of the most common is phishing emails, where attackers craft emails with convincing pleas that cause people to click on a link.
In this case, let’s say the attacker sent something like:
You won’t believe how cute this dog is:
evilwebsite.com/attack.html
You may not be super enthusiastic about clicking a link that says evilwebsite.com, but in real life, the attack website could have a much more mundane name, or be disguised with a URL shortener like Bitly.
Attackers will often send these messages out to vast numbers of people to increase their chances of success. Let’s say that one person is fooled by the email and visits evilwebsite.com/attack.html. They navigate to the website, where the malicious password-changing form is triggered automatically. The form with the attacker’s new password gets sent by the victim’s browser to yourfavoritewebsite.com.
The forged request seems real to the server
The malicious form is sent as a POST request from the victim’s browser, and it includes the victim’s session cookie. When the victim is both logged in and the session cookie is attached to the request, yourfavoritewebsite.com assumes that the request legitimately came from the victim and it accepts the request. It changes the password to the value the attacker specified, “csrfattack”.
Yourfavoritewebsite.com doesn’t directly send anything to the attacker–this isn’t the point of CSRF attacks. Instead, it changes the state of data stored on its server as requested by the attacker. In this case, the password was changed to “csfrattack”, which the attacker knows, and the victim doesn’t.
This locks the victim out of their account while giving the attacker complete control to do whatever they want. They could then steal data, drain the bank account, or commit a range of other crimes, depending on what type of account it is.
As we mentioned earlier, the attacker couldn’t directly steal data through a CSRF attack, because the server does not communicate with the attacker. Despite attackers being limited to changing the state of data on the server, CSRF attacks give them an excellent foothold to mount further attacks.
If the attacker’s main aim was to steal data, they could accomplish this by first using a CSRF attack to change the password or email address to one that they know (or control, in the case of email address). Once they have done this, they can take over the account and steal whatever they want.
GET requests in CSRF
Now that we have covered how POST requests can be used in cross-site request forgeries, we will take a look at what GET requests can do. Let’s say you have an online account with your bank at vulnerablebank.com. An attacker discovers that vulnerablebank.com is vulnerable to cross-site request forgery attacks, and sees this as an opportunity to make some money.
Incorrectly implemented GET requests
The bank has ignored HTTPS standards and it uses GET requests to process funds transfers. If you remember our section on the different HTTP request types, GET requests are supposed to be a safe request type that only retrieves data. They aren’t supposed to intentionally change data on the server. Instead, they are just supposed to retrieve it. Unfortunately, developers don’t always pay attention to the standards.
While it is unlikely for a major banking platform to use GET requests in this way today, we see so many incredible lapses in security that even this wouldn’t be too shocking. Even though it would be surprising for a modern banking website to use GET requests in this way, the example that we will cover still gives a good demonstration of how GET requests can work.
Researchers from Princeton discovered a similar but more complex version of the vulnerability that we will discuss. It affected a banking firm named ING Direct. The attack used a combination of both GET and POST requests, however, it was more than a decade ago.
Predictable parameters
Not only does vulnerablebank.com use GET requests for state changes, but it also has predictable parameters that make it easy for the attacker to abuse the system. Let’s say that funds transfers take the following form:
GET http://vulnerablebank.com/transfer.do?acct=name&amount=$XXX HTTP/1.1
If you were to make a funds transfer to your friend, Jane, it might look something like:
GET http://vulnerablebank.com/transfer.do?acct=jane&amount=$100 HTTP/1.1
It would probably say Jane’s account details instead of ‘jane’, but that isn’t particularly important for the purposes of our example.
If the attacker has their own account with the bank, or discovers the URL parameters for funds transfers via other means, it makes it relatively simple for them to craft a URL that allows them to steal money. They could send $1,000 to their own account by crafting the following GET request:
GET http://vulnerablebank.com/transfer.do?acct=attacker&amount=$1000 HTTP/1.1
While the attacker now has the URL they needed to transfer funds to their own account, they can’t just send it to the vulnerablebank.com themselves. The server won’t accept this GET request for the funds transfer unless their victim is logged in, and it receives the session cookie with the unique session ID.
The good news for the attacker is that vulnerablebank.com also has a cross-site scripting (XSS) vulnerability. These aren’t necessary for CSRF attacks, but they allow the attacker to launch a stored CSRF attack, which has a higher likelihood of success.
Stored cross-site request forgeries
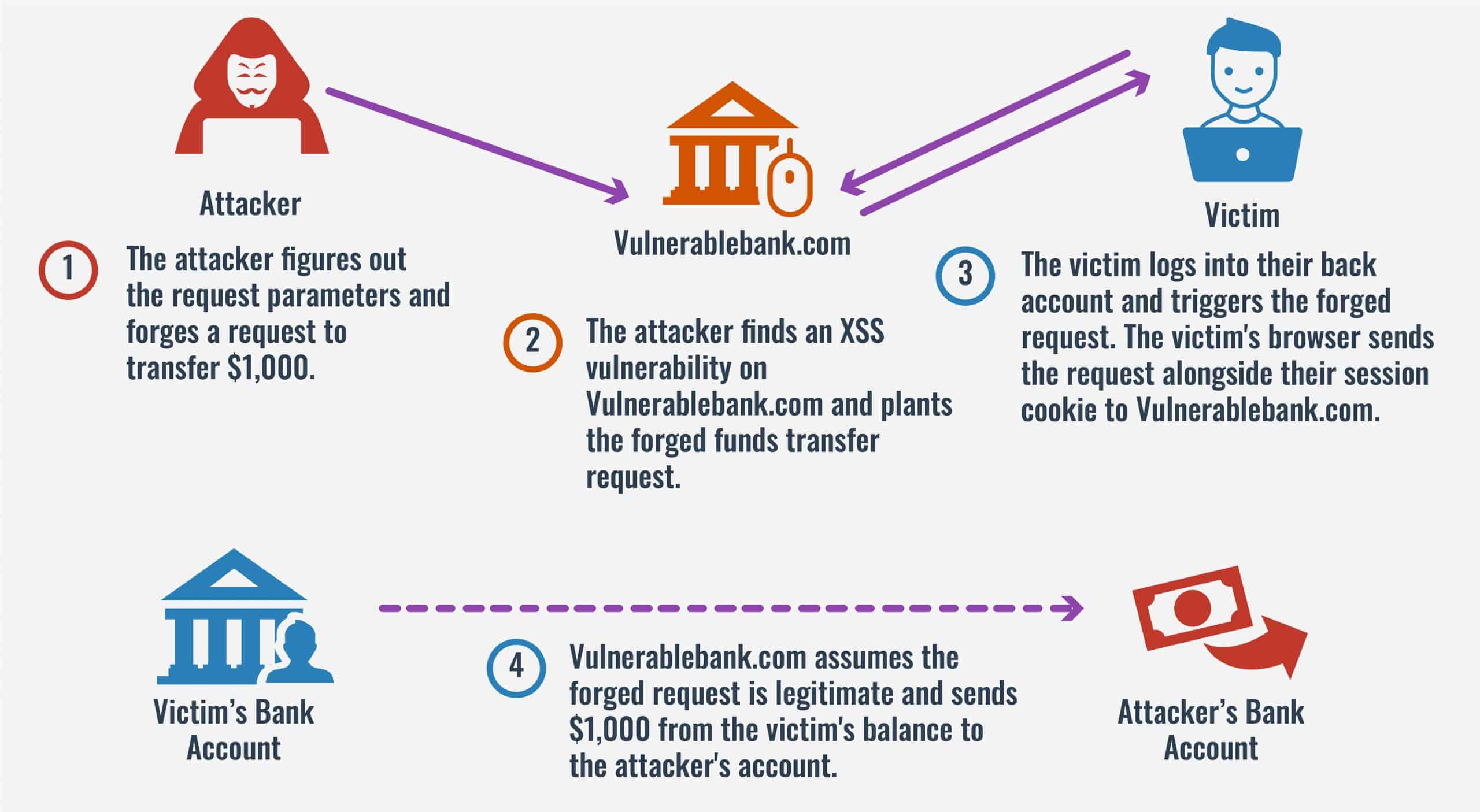
In this example, the malicious request will be stored on vulnerablebank.com, instead of on another website, which was the case in our POST request example from above. This is the key distinction between stored CSRF and other CSRF attacks—in a stored attack, the malicious link is hosted on the same site that is also being targeted.
We are demonstrating a stored CSRF simply to show some of the variance in CSRF attack methods. It isn’t a necessary part of these GET request attacks. The POST attack that we showed above could also have been a stored CSRF and included the malicious form on yourfavoritewebsite.com (if the attacker had found a cross-site scripting vulnerability on yourfavoritewebsite.com).
The advantage of these stored CSRF attacks is that they increase the likelihood of the victim succumbing to the attack. This is because they will usually be logged into the targeted website already, and are more likely to come across the page where the malicious request lies.
With this approach, the attacker doesn’t need to come up with a carefully crafted phishing message to lure the victim to another website where the malicious request is hosted. All they have to do is hope that the victim stumbles across the page on the very same website, which is a much simpler task. The attack may be triggered automatically upon the victim’s arrival, or the attacker may need to trick them into clicking, but either way, stored CSRF attacks still remove a major hurdle.
While this certainly makes stored CSRF attacks advantageous, they do require the attacker to find an XSS vulnerability. These vulnerabilities are the result of websites with poor validation and sanitization practices, which can allow attackers to execute malicious scripts through the input fields. However, many websites have security mechanisms in place that make this impractical.
Planting the malicious request
With the forged request in hand, as well as an XSS vulnerability, the next step for the attacker is to plant the malicious request on one of vulnerablebank.com’s pages that the victim is likely to visit.
Let’s say that the search function in the Transaction History page has the input vulnerability, which allows the attacker to enter their own code, which the website will then execute. The Transaction History page also makes a good place to store the malicious script, because most users visit it relatively frequently.
The attacker could plant an enticing link on the page that encouraged the victim to click on it. Perhaps something along the lines of “Enter our $1,000 prize giveaway!”. It might look something like:
<a href=”http://vulnerablebank.com/transfer.do?acct=attacker&amount=$1000 “>Enter our $1,000 prize giveaway!”</a>
Once the attacker has the link on vulnerablebank.com, all they have to do is wait for the victim to log in. In this case, let’s say that it’s you. When you enter your username and password, the bank website’s server plants a session cookie in your browser with the unique ID.
Perhaps you check your balance, then you go through your transaction history to see what you have been spending your money on. While you are scanning through, you notice a link for a $1,000 prize giveaway. You click on the link, figuring that it can’t hurt to give it a shot.
Unfortunately, you were very wrong. By clicking the link, you have sent the GET request from your web browser. Since you are already logged in and your browser has the session cookie, vulnerablebank.com’s server thinks that it’s a legitimate request from you. Because it thinks you made the request, it accepts the transaction and sends $1,000 from your account to the attacker’s. You may not even realize it happened.
Again, you may notice that the website’s server didn’t send any information directly to the attacker’s computer or website. Instead, it sent money from your account into the attacker’s account. Once more, this is because CSRF attacks focus on changing the state of data on the server. Despite this limitation, the attacker still figured out a way that they could use a state change to their advantage–by changing the state of your account balance.
The many variations in cross-site scripting attacks
We’ve discussed two separate cross-site request forgery attacks that have pretty significant differences. Now that you understand the basic structure of these attacks, it may be helpful to go through and list all of the ways that they can vary. It can be difficult to get your head around the many moving parts in cross-site request forgeries, so this summary should hopefully give you a clearer picture.
POST vs GET requests
You may have noticed that our POST request example required the attacker to trick the victim into submitting a form, while the GET request only needed a URL with the parameters in order for the attacker to achieve their desired result. This means that when GET requests are incorrectly used to alter data (which goes against the standard), it tends to be much easier for attacks to exploit them.
The other HTTP requests we listed in the HTTP request section can also be used in cross-site request forgeries, however, this is less common.
Stored CSRF vs hosting the attack elsewhere
We just discussed how stored CSRF attacks are advantageous because:
- They increase the likelihood of the victim being exposed to them.
- There is a greater chance of the victim already being logged in
- They eliminate the need to host the attack elsewhere.
Together, these factors make stored cross-site request forgeries much easier because hackers don’t have to come up with a way to lure the victim to another website.
Stored CSRF attacks require a cross-site scripting (XSS) vulnerability that lets hackers input malicious code. Hackers often insert iFrame or IMG tags in the fields to set up their attacks.
In many instances, the attacker will not be able to find the necessary XSS vulnerability, so hosting the attack on another site and then tricking the victim into visiting it is the only option.
Luring in victims
If a stored CSRF attack isn’t possible, hackers still have a range of options for attracting potential victims to the website where they host the malicious request. One common option is through phishing. This involves either sending out emails en-masse, or in the case of spearphishing, highly targeted emails to specific people.
Either way, the aim is to create a message that convinces potential victims to click on the link, which then takes them to the website where the malicious request awaits them.
Another option is for attackers to post links to their malicious website in various places online. This could be on their own blog, in forum posts, in their profile, in comments, and in many other places. Social media is another option for sharing these links. The specifics of where don’t matter that much. The most important aspect is that it somehow fools users into clicking.
Attackers may also post the link with image tags. This is often done on forums that allow images, but not JavaScript. They can attempt similar tactics across the web, wherever attackers can input HTML tags into input fields.
Does the user need to click, or is it automatic?
Whether the malicious request is stored on the targeted website, or another website under the attacker’s control, it’s best to trigger the attack automatically as soon as the potential victim stumbles across the page. This removes an extra step, which is really just one more opportunity for the potential victim to escape.
HTTP requests can be automatically triggered by certain JavaScript tags. One example of this are the AJAX requests that are used for autocompleting search suggestions. Another common example are <img> tags, which generate GET requests to the linked image, so that the image can be automatically loaded from its source.
These automatically triggered requests allow attackers to launch their malicious requests without any user interaction, and they can take place without the user even being aware that it’s happening.
The outcomes of CSRF attacks
Cross-site request forgery attacks change the state of data on the server, rather than directly steal it. Attacker’s don’t bother forcing the victim to retrieve data from the server, because they won’t receive the response, only the victim will. This is why CSRF attacks involve state changes that will be beneficial to the attacker.
Our example of a POST request CSRF attack focused on changing the password to one already known by the attacker–changing the state of data on the server to something that helps move them further toward whatever nefarious goals they have. The attacker can reach a similar end result by changing the victim’s recovery email address to one that they control because it allows them to reset the password to one of their choosing.
From this point, an attacker can essentially do anything with the account that the user is authorized to do. Obviously, this varies according to the type of account, but it could include things like:
- Reading or sending emails as though they were the victim.
- Making posts on social media.
- Abusing the trust that others have in the victim’s account, and tricking them into becoming new victims.
- Stealing the victim’s personal information for further crimes.
- Making online purchases.
There is a wide range of other attacks and crimes that a hacker can commit once they have control of the victim’s account, including extortion and fraud. When CSRF attacks are used to take over an account, they basically give attackers the foothold they need to launch whatever crime campaign they have dreamed up.
This can have far wider ramifications if the victim’s account has a privileged role within the website, such as an administrator account. If an attacker manages to change the email or password of a privileged account, they could have full control over the web application’s functionality and its data. This level of access could be truly devastating for the users and could result in large-scale data breaches, theft, and more.
In addition to these wide-reaching attacks, hackers can also focus on the narrower state-changing techniques that we saw in our GET request CSRF example. Even though the attacker never took control of the victim’s account, they were still able to initiate state changes that benefited them. Of course, stealing large amounts of money would still be devastating to the user, even if their account was never completely taken over.
Cross-site request forgery (CSRF) vs cross-site scripting attacks (XSS)
Not only do cross-site request forgeries and cross-site scripting attacks have similar names, but there are also overlapping elements between these two types of attacks. While this can be confusing, there are a couple of major differences that should help you be able to tell these attacks apart:
- XSS attacks involve exploiting input validation vulnerabilities, while CSRF attacks exploit predictable parameters.
- XSS attacks allow attackers to directly steal data, because they give them a way to circumvent the same-origin policy. In CSRF attacks, hackers do not get a response from the server, so they cannot directly steal information. However, they can use CSRF attacks to change the password or the email associated with an account, and then steal data.
How to prevent cross-site request forgeries
There are a range of mechanisms for preventing cross-site request forgeries. Some of these include:
Implementing requests correctly
It’s important that your website implements GET requests as specified by HTTP standards and does not allow them to alter the state data on the server. As we have shown above, this can lead to CSRF vulnerabilities. While this can prevent some of the easiest and most egregious CSRF attacks, you will need to also implement other tactics to protect your users appropriately
Requiring unique tokens in the request parameters
As we have mentioned throughout, one of the requirements for a successful CSRF attack is to have predictable request parameters. If the attacker can figure out all of the information they need to request a specific action, all they need to do is find a way to trick the victim’s browser into sending that request.
With this in mind, an attacker cannot succeed in their CSRF attack if they do not know all of the correct input parameters that are needed for a specific action. Therefore a website can prevent cross-site request forgery attacks by requiring inputs that an attacker has no way of figuring out.
This is generally achieved with some type of anti-CSRF token. There are various ways to accomplish this, but the same rough idea applies. Let’s take the GET request that we used in our example to initiate the funds transfer:
GET http://vulnerablebank.com/transfer.do?acct=name&amount=$XXX HTTP/1.1
In our example, the attacker could successfully transfer money into their account by adding in their own name and the desired amount, like so:
GET http://vulnerablebank.com/transfer.do?acct=attacker&amount=$1000 HTTP/1.1
But what if we added a unique number that was complicated enough to be unfeasible to guess? If the server created a different token like this each time it served the website to you, the GET request for a funds transfer may now look something like this:
GET http://vulnerablebank.com/transfer.do?acct=name&amount=$xxx&token=872ea94c9b8a9381bd09238bc92847e048733bae1 HTTP/1.1
If this unique token is different each time the web page is served to you, the attacker will be unable to guess the correct parameters for the request, like they could in the earlier example. If they cannot enter valid parameters, the server will not accept the request, preventing the attacker from being able to transfer funds or succeed with other forged requests. The same basic logic applies to POST requests.
Implementing a challenge and response
Another tactic is to require further user involvement via a challenge and response mechanism. If one of the main dangers from cross-site request forgeries comes from the fact that they are initiated without user involvement, one solution is to require them to act before these state change requests are accepted by the server.
This can be achieved through:
- CAPTCHAs.
- One-time tokens.
- Requiring the user to enter their password once more.
If these additional security mechanisms are implemented, a cross-site request forgery would trigger the user to enter one of the above inputs before the request is approved. In most cases the user will realize that something strange is happening, and put a stop to the forged request instead of performing the desired action.
Limiting cross-site request forgeries
Cross-site request forgeries are a significant online threat, but there are a range of mechanisms that can help to mitigate them. If you operate a website, you can protect your users by following the strategies listed above.
While it may seem like an additional hassle, keeping them safe from attacks can be helpful for the long-term success of your website. Would you keep using a site that didn’t bother protecting you from the devastating effects of cross-site request forgeries?