
Relational databases are a popular form of data storage with businesses because they reduce the amount of space needed for storing corporate transactions and documents.
The Relational Database Management System (RDBMS) creates storage formats and manages access to data.
As the repository of essential data, the relational database is critical to the survival of the business. Failure of the RDBMS or security breaches that allow intruders to steal or destroy data could ruin your company. So, this guide will also outline practices that will help you to protect your databases.
Relational databases are not suitable for every business application. The process behind getting data in and out of the database can be cumbersome. The recommended practice of indexing data can actually slow down the insert process. Badly-organized indexing can also create problems with data access through clashes of priorities. In this guide, you will learn the business functions for which relational databases work well.
The relational model
The “relational” term refers to the relational model, which was defined by Edgar Frank Codd, better known as E F Codd, in 1969 while he was working as a computer scientist for IBM.
There are 13 requirements in Codd’s definition for a database to be categorized as relational and almost none of the real-world implementations comply with all of these. However, the two main requirements for a relational database, in layman’s terms are:
- Data should be normalized.
- Data should be accessible through relational operators.
These two categories are explained further below.
Data normalization
Data is organized into “entities” and each entity has “attributes”. When planning a relational database, you gather all of the business’s documents and write down the headings that are there. For example, an invoice may have Invoice Number, Invoice Date, VAT or EIN Number, Business Name, Business Address, Customer Name, Customer Address, Invoice Line Number, Item Code, Item Description, Item Unit Price, Quantity, Line Total, and Invoice Amount. This collection of data has information at several levels. The process of sorting out the headings into different groups is called “normalization”.
There are many stages to normalization, but in practice, you only need to perform the first three. These are:
- First normal form (1NF): Separate out repeating groups
- Second normal form (2NF): Separate out partial key dependencies
- Third normal form (3NF): Separate out attributes that are better identified by fields other than the primary key.
By the end of these three steps, each attribute in the group is dependent on the key, the whole key, and nothing but the key.
First normal form
Let’s take a look at an invoice example. In first normal form, we separate out repeating groups. Clearly, there are two levels of data on the invoice: the header information and the line data. In order to work out which attributes belong in which group, pick a field that seems to be the primary data element of the document – this is a unique identifier for this invoice and so must be the Invoice Number field. This primary identifier is called a “constraint” because you have to force uniqueness for this field on all records in the database. This will become the “primary key” of the table.
Ask how many times each of the other fields have different data for each invoice number. You will end up with two groups: INVOICE HEADER with attributes Invoice Number, Invoice Date, VAT or EIN Number, Business Name, Business Address, Customer Name, Customer Address, and Invoice Amount; and the INVOICE LINE with attributes Invoice Line Number, Item Code, Item Description, Item Unit Price, Quantity, and Line Total.
Line Number would not uniquely identify each record in the database, so the INVOICE LINE group needs Invoice Number added to it. In this case, the table has a composite key. Invoice Number is also a foreign key to the INVOICE HEADER group.
In the case of the INVOICE HEADER group, the Invoice Number should be unique for each invoice. However, that can’t be guaranteed, so it is usual to create a hidden unique identifier field on the table, which will be populated from a sequence to ensure that there can never be duplicated values in this field.
By adding Invoice Header ID to the INVOICE HEADER table, we provide a better value as the foreign key in the INVOICE LINE group, so we add an Invoice Header ID field into that table. It is quicker to “join” on one field when trying to specify a single record, and so it would be better to create a unique identifier for records in the INVOICE LINE group, called Invoice Line ID. Invoice Header ID is now the primary key of the INVOICE HEADER group and Invoice Line ID is the primary key of the INVOICE LINE group. Now we call the groups “entities” and the fields “attributes”.
Second normal form
To get to the second normal form, you need to split out attributes that are not dependent on all of the elements in a composite key. This requires no work in the INVOICE HEADER entity. The INVOICE LINE entity did have a composite key (Invoice Number and Line Number) but this has been replaced by the unique identifier Invoice Line ID. So, there are no partial key dependencies here.
Third normal form
In this step, you should split out attributes that are better identified by another attribute in the group. In the case of INVOICE HEADER, the attribute Business Address is more dependent on Business Name than the primary key. So, this would create a table called BUSINESS DETAILS, which would have attributes Business Name, and Business Address. It would be better to split out the lines of the business address into Address Line 1, Address Line 2, City, State, Country, and Postal Code. The VAT or EIN Number should also be removed from INVOICE HEADER to this entity.
Customer Address is related to Customer Name more than Invoice Header ID, so these fields should be split out, creating a CUSTOMER entity and a CUSTOMER ADDRESS entity.
Business Name is not a unique identifier, so you should add a Business Details ID field. You might invoice from several addresses. If this is the case, then you need to split out the address details to another entity called BUSINESS BRANCH. Add a unique identifier to this entity: Business Branch ID.
The CUSTOMER and CUSTOMER ADDRESS tables also need unique identifiers Customer ID and Customer Address ID.
You need to put a reference in each of the entities that have lost attributes to new entities so that they can relate to them. Therefore, Business Branch ID needs to go into the BUSINESS DETAILS entity, Customer Address ID should be added to CUSTOMER, and Business Details ID and Customer ID need to be attributes of the INVOICE HEADER attribute.
In the INVOICE LINE entity, Invoice Number is no longer needed, because it is wholly dependent on Invoice Header ID and already exists in the INVOICE HEADER entity. Item Code, Item Description, and Item Unit Price are all attributes of the item, not the invoice line, so these fields need to be split out to a new entity, called ITEM. You need to put a unique identifier Item ID on the ITEM entity and add that attribute to the INVOICE LINE as a foreign key.
Normalized data
In the example above, you now have seven entities:
INVOICE HEADER
- Invoice Header ID
- Invoice Number
- Invoice Date
- Business Details ID
- Customer ID
- Invoice Amount
BUSINESS DETAILS
- Business Details ID
- Business Name
- Business Branch ID
- VAT Number
BUSINESS BRANCH
- Business Branch ID
- Branch Address Line 1
- Branch Address Line 2
- Branch City
- Branch State
- Branch Country
- Branch Postal Code
CUSTOMER
- Customer ID
- Customer Name
- Customer Address ID
CUSTOMER ADDRESS
- Customer Address ID
- Customer Address Line 1
- Customer Address Line 2
- Customer City
- Customer State
- Customer Country
- Customer Postal Code
INVOICE LINE
- Invoice Line ID
- Invoice Header ID
- Invoice Line Number
- Item ID
- Quantity
- Line Total
ITEM
- Item ID
- Item Code
- Item Description
- Item Unit Price
As you can see, a relatively simple document has become a lot of structures. However, splitting out the data in this way will greatly reduce the amount of data that needs to be stored.
Database design
The next step is to put all of these entities in a plan, showing the attributes of each and marking the primary keys. It is then necessary to add on the relationships between these entities, which run from the foreign key in one table to the primary key in another.
This relationship must either be one-to-many, or many-to-one. This means that for an instance of a record in one entity, there must be several records in the related table. If you discover a one-to-one relationship, those two entities should be merged. If you see a many-to-many relationship, you must break it up by inserting an intermediate entity that will have a many-to-one relationship with the each of the two original entities.
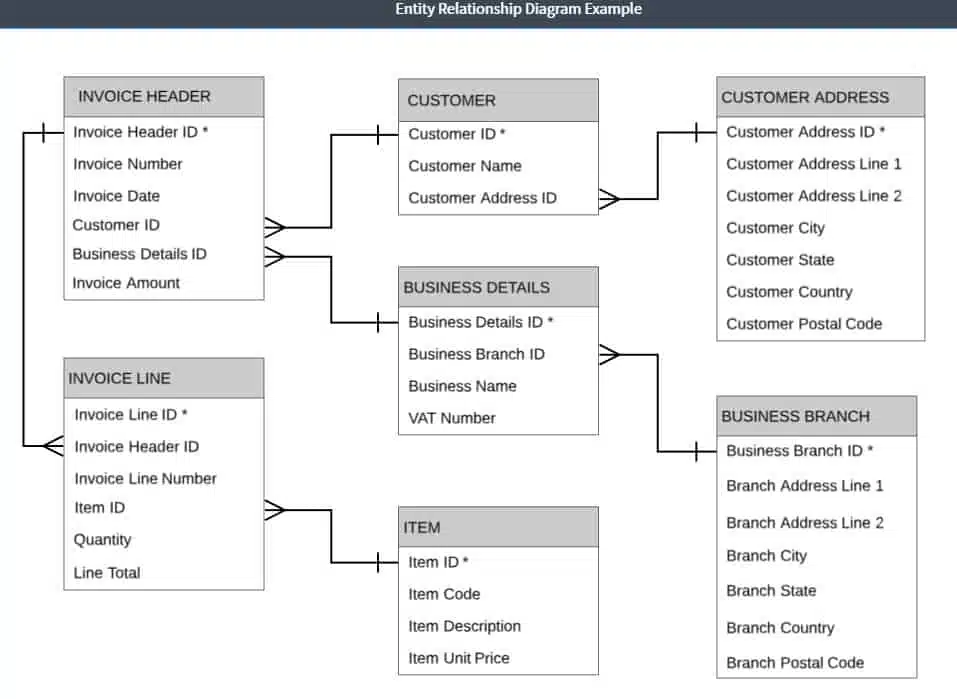
The plan that this work creates is the Entity-Relationship Diagram, which is the foundation document for the relational database.
Database creation
Each of the elements in the Entity-Relation Diagram translates into database objects:
- Entity = table
- Attribute = table column
- Constraint / primary key = unique index populated by a sequence
RDBMS have several command sets. Objects are created by a Data Description Language (DDL). The command to create an object is:
CREATE <object type> <object name> <object details>For example:
CREATE TABLE customer (customer_ID INT NOT NULL,
customer_name VARCHAR(200) NOT NULL,
customer_address_ID INT NOT NULL
CONSTRAINT PK_customer PRIMARY KEY (customer_ID));The column definitions need to include a data type. The NOT NULL option prevents records from being inserted into the table without that field being populated – an essential feature of a primary key column and an important requirement for a foreign key.
DDL also includes commands to change objects (ALTER) and delete objects (DROP).
Data Query Language
Part of the definition of a relational database is the requirements for a Data Query Language (DQL) that implements the eight relational operators that were defined by E F Codd. These are:
- SELECT
- PROJECT
- JOIN
- PRODUCT
- UNION
- INTERSECT
- DIFFERENCE
- DIVIDE
These are all implemented by an SQL command, SELECT.
The basic format of this command, which is called a “statement,” is:
SELECT <column names>
FROM <table names>
WHERE <condition>If you only want to select data from one table, the SQL statement is very straightforward. You just have to list the columns that you want to see or use a wildcard (“*”) to see all columns:
SELECT *
FROM customer;If you need to see a specific record, you should put a condition in the WHERE clause:
SELECT *
FROM customer
WHERE customer_ID = 1232;The main work of a programmer or data searcher with relational databases is to reassemble all of the data that was split out into separate tables. This is called a “join” and is performed by both the FROM and WHERE clauses:
SELECT b.invoice_line_num,
c.item_code,
c.item_description,
b.quantity,
c.item_unit_price,
b.line_total
FROM invoice_header a
invoice_line b,
item c
WHERE a.invoice_num = “MX 1003 100”
AND b.invoice_header_id = a.invoice_header_id
AND c.item_id = b.item_id;SELECT is the only SQL command that qualifies as Data Query Language (DQL).
Structured Query Language
Access to data is performed by the Structured Query Language (SQL). This encompasses Data Description Language, a Data Manipulation Language, and a Data Query Language.
Although initially developed to perform straightforward data fetches, SQL was forced into the role of programming language.
It is very difficult to produce an entire program with SQL because you cannot store a series of instructions. Even if you create a script that includes a number of SELECTs, each will perform an independent data fetch from the database. You cannot store values in variables or link SELECT statements together with control instructions such as conditional branches. Essentially, the SELECT statement is one big loop because it will execute repeatedly until all matching records have been retrieved from the database.
It is possible to link SQL statements together with clauses such as MINUS and it is also possible to use a query to feed in values to the selection criteria contained in a main query – this strategy is called a “sub-query”.
Database users
There are four groups of users of a relational database:
- Database Administrator
- Programmer
- Data entry user
- Data end user
Of these four, only the Database Administrator (DBA) will have unrestricted access to the database. It is common practice to create copies of a database for development. Programmers will get access to a development copy. The programmer will get DDL and DML (Data Manipulation Language) rights on this database but won’t have any access rights to the live database. Often, DBAs will create a third instance of the database for testing. This is usually called “sandbox,” or “snd”.
The Data Manipulation Language gives the user the right to insert, update, or delete records in created tables. These are the rights that data entry users get. Those data entry users might be a pool of clerks in a large organization, call center staff, or even customers themselves. These users almost never get direct access to the command line of the database. Instead, developers create forms that control the data manipulation access.
Data end users also don’t get command-line access to the database. Instead, they access data through an interface and use data mining tools that have graphical interpretation features built into them, such as charts and graphs.
It is very important to limit command-line access to the database and particularly important to limit the possession of the administration password to the DBA. Developed interfaces limit the actions that data end-users can perform on the data and include validation scripts in the forms written for data entry users.
In order to prevent unauthorized access to data, the data mining tools and data entry forms should all be password protected and all actions on the database should be logged, identifying each user’s activities.
RDBMS performance issues
Although RDBMSs are very effective at reducing the repetition of data, their data access procedures can sometimes be a crippling overhead. Very large tables of data can take hours to process, particularly if a query includes joins to tables with many complicated sub-queries. It is often necessary to run reports overnight in order to avoid user complaints over their slowness to complete.
This problem is the main reason that RDBMSs are less popular in the field of marketing. RDBMSs are great for traditional business activities, such as accounting, but since marketing got into the technique of gathering and analyzing big data, other data storage and manipulation systems have been given greater prominence.
The successful rival to RDBMS in the processing of big data is a category of database systems that is called NoSQL. In order to keep your RDBMS running at acceptable speeds, the DBA has to perform a number of optimization tasks. These include clearing out gaps and reallocating the memory used by the system to eradicate gaps created by deleted data and making the RDBMS occupy a contiguous area of storage and memory.
The haphazard creation of a database and poorly-monitored alterations and extensions can also impair RDBMS performance, so periodic reviews of the objects in a database in a “spring clean” can help to optimize the speeds at which data can be inserted and retrieved. Similarly, scripts and programs that perform complex actions on data as it is retrieved can often be improved to enable them to return data faster. Fortunately, there are tools available to assist with database optimization tasks.
Database performance tools
One problem with delivering speedy results from a database is that there are many different services involved in getting data to the users. There is no point having a speedy database if the network is slow. Therefore, system administrators need to ensure that the path of delivery is optimized as well as the database.
SolarWinds Database Performance Analyzer (FREE TRIAL)
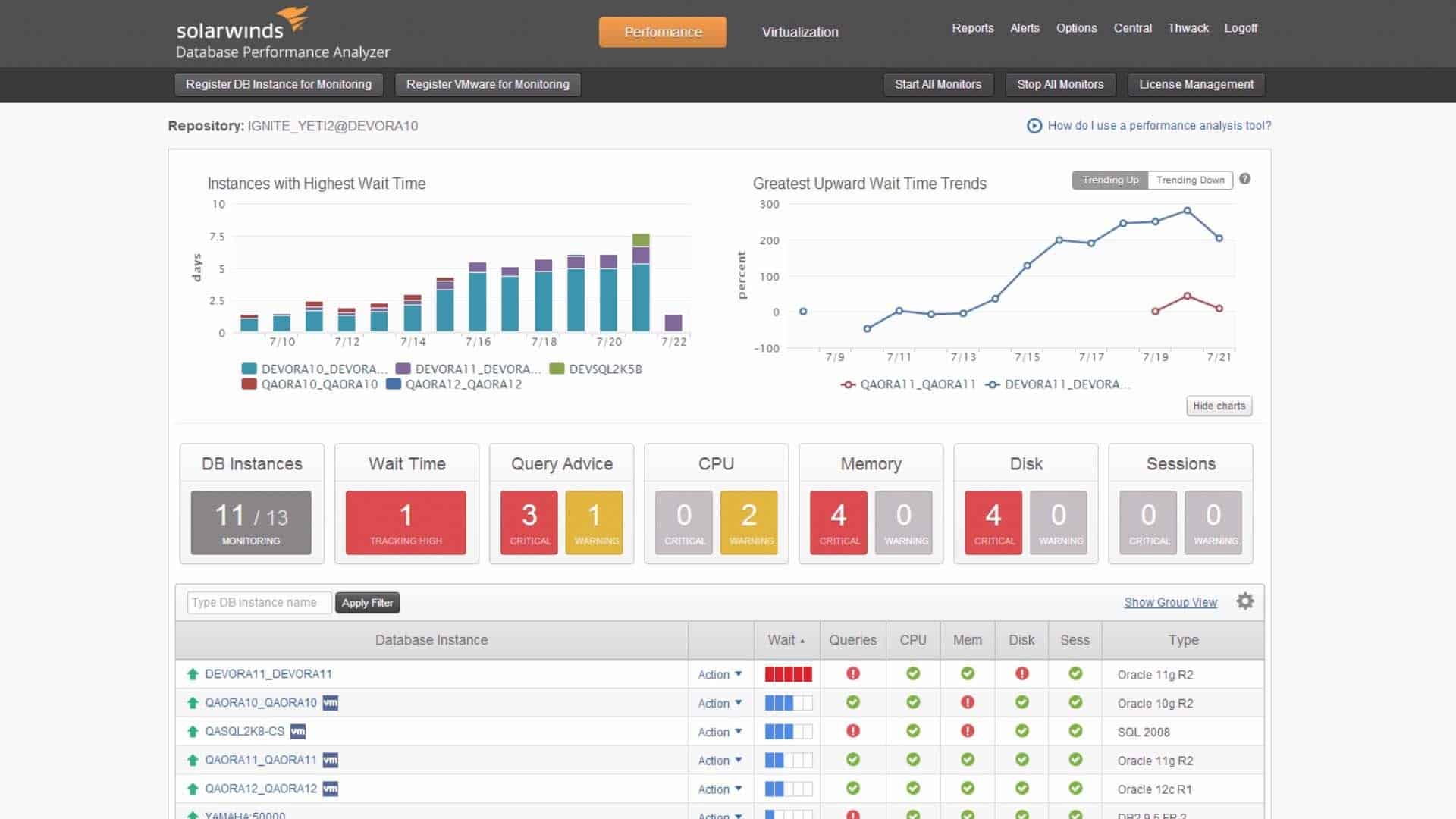
The SolarWinds Database Performance Analyzer is able to check on the performance of your database, including data delivery channels. The tool is able to test your hardware, your RDBMS, code, and database object efficiency.
Why do we recommend it?
SolarWinds Database Performance Analyzer is a specialized tool for RDBMS management. It measures live database access events, which provide the ultimate test of a database’s design. You can tune memory allocation and examine database objects to improve performance with this system and decide either queries or database objects need to be changed.
The tool is able to optimize SQL Server, Oracle, MySQL, DB2, SAP ASE, and Cloud RDBMSs. The performance analyzer is able to check on the statuses of the server that supports the database and check on response times at regular interval, producing performance graphs in the dashboard. Those metrics also let you see summaries of all of the activities being performed on the database at any moment. The monitor doesn’t capture any data being processed, so it doesn’t break confidentiality.
When migrating new code and objects from the dev database, through sandbox on to the live system, you can trial the impact of these changes through the Database Analyzer.
This analyzer has a machine learning module that establishes a baseline of normal performance, raising alerts when activities deviate, and raising the likelihood of strain on the system. The tool works both with live data and historical performance metrics to give you a timeline of database performance.
Who is it recommended for?
The product list of SolarWinds provides packages that include database monitoring as part of their functions. However, if you need a really focused database analyzer, you would be better off with this tool. So, the purchase of this tool would be driven by the requirements of a DBA or a database developer.
This is a paid tool, but you can get it on a 14-day free trial.
Related post: Best Database Management Tools
Managing an RDBMS
Remember, when you run an RDBMS, there are many performance factors to take into account to ensure satisfactory operations. Access controls are also important and you need to limit the number of people who get the admin password. Interfaces enable you to control the amount of access regular users get to the database. However, they also introduce an extra potential point of failure.
Keep track of performance issues and try to head off disaster with a database monitor and analyzer. An automated tool to monitor your network and improve transfer speeds will also help you to keep data delivery at acceptable speeds.
Relational database management systems FAQs
What is relational in database management system?
A relational database management system (RDBMS) is a framework for storing data in tables. The “relational” part of the name indicates the ability to join tables together in the course of data querying. Relations between tables are maintained through common fields. In one table, that column should be the primary key on which an index is imposed. In the table to which that column links, the connecting field is known as a foreign key.
What is an example of a relational database management system?
Relational database management systems (RDBMSs) all have common characteristics, which include a structured query language (SQL). While database objects are almost identical in all RDBMSs, the SQL used for each is a little different. Examples of RDBMSs include:
- Oracle
- PostreSQL
- SQL Server
- MySQL
- IBM DB2
- Microsoft Access
What is a relational database management system most commonly used?
Relational databases hold records in tables and those tables can be logically joined together to extract stored data. So, they are very widely used to hold reference information, such as an address book, and transactional information, such as a list of invoices. The ability to join tables together means that all of the information of an address does not need to be stored on the record of each invoice. This method of referencing is very efficient and so relational databases are very widely used in business administration systems, known as ERPs. They also lie behind the chopping cart pages in websites.

 Guide){kind=link}