

Browser fingerprinting is an investigative method that involves matching browser activity to identify individual users. It can be used to trace online activities to a specific person, and as such, can represent a violation of privacy. Even using a VPN might not be enough to avoid browser fingerprinting.
So how can you protect yourself against invisible browser fingerprinting and improve your privacy? We explain how browser fingerprinting works and how to stop browser fingerprinting.
What is browser fingerprinting?
A common investigative technique in law enforcement is to collect fingerprints at the scene of a crime. At the time of collection, it’s not known who those fingerprints belong to, so the goal is wholesale collection for later analysis. Those fingerprints are later matched against a database of fingerprints with known owners to identify specific people.
Web browser fingerprinting, also called canvas fingerprinting, works in a similar way. It involves the wholesale collection of browser identification points that can then be matched against the browser characteristics of known people. In both types of fingerprinting, analysis may not reveal the identity of a person but can show that the same person performed different activities.
Most privacy enthusiasts are aware that the primary way in which they can be identified online is through the use of their IP address. TCP/IP, the protocol suite that the internet uses, necessarily requires that your IP address be sent with every request so the web server knows where to send the response.
Virtual Private Networks (VPNs) have become popular over the past few years as a way to hide your real IP address. You essentially borrow an IP address (shared by many people) from your VPN provider. Traffic in the web server’s log simply shows the VPN’s IP address.
See also: Best VPNs for Privacy
But what else does your web browser send that a VPN cannot scrub out? Much of that depends on your browser configuration, but some of it simply cannot be helped. Correlating the data in your browser’s requests can allow someone to identify you, even if you’re using a VPN.
How does browser fingerprinting work?
The data collection can be completed in two ways; on the server and through client-side technologies like JavaScript and Adobe Flash®.
Server-side collection
Website access logs on the server can collect data that is sent by your browser. At a minimum, that is usually the protocol and URL requested, the requesting IP address, the referer (sic), and the user agent string.
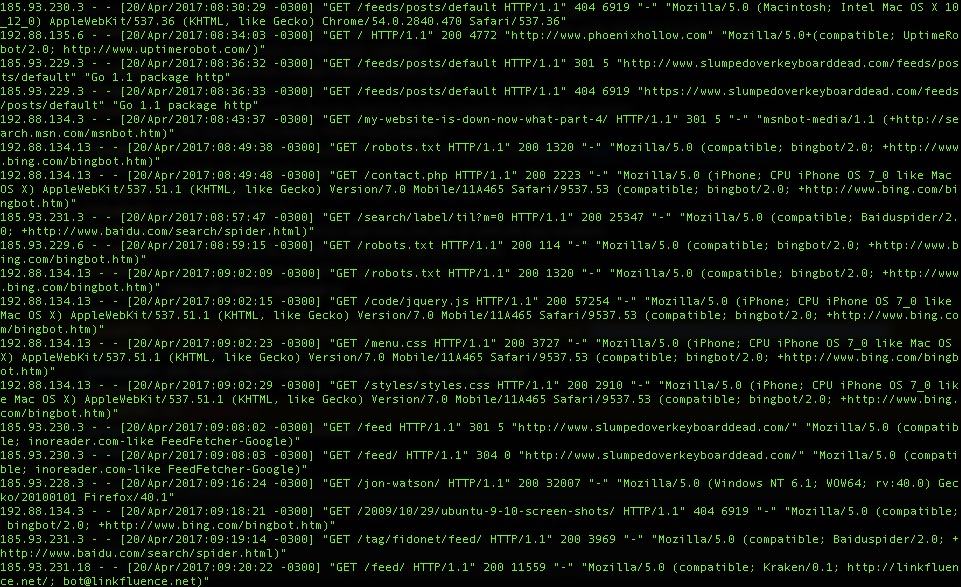
Let’s look at a standard Nginx access log entry of a request using the Safari browser. It looks like this:
11.22.33.4 - - [18/Apr/2017:08:04:17 -0300] "GET /using-expressvpn-with-ubuntu-linux-mint-or-debian-linux/HTTP/1.1" 200 12539 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/603.1.30 (KHTML, like Gecko) Version/10.1 Safari/603.1.30"
My IP address, browser, and operating system are included in the request. The browser and operating system are included in the user agent string which is this part of the request:
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/603.1.30 (KHTML, like Gecko) Version/10.1 Safari/603.1.30"
If I load the same page using Google Chrome, the only difference is that the user agent now shows as Chrome. The log shows the same IP address and the same operating system. Two points are not enough to draw a concrete comparison, but it is enough to indicate that these two requests could have come from the same person.
11.22.33.4 - - [18/Apr/2017:08:05:36 -0300] "GET /using-expressvpn-with-ubuntu-linux-mint-or-debian-linux/ HTTP/1.1" 200 12581 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36"
Web servers can also be configured to log much more data in their access logs by using log format specifiers.
In addition to the information recorded in web server access logs, browsers also send a series of headers. The web server needs to know what types of content and compression the browser understands. It’s also extremely common for cookies to be exchanged between browsers and web servers. In the developer tools of my Chrome browser, I see that these headers were sent with my request and can be further used to fingerprint by browser:
:authority:slumpedoverkeyboarddead.com
:method:GET
:path:/using-expressvpn-with-ubuntu-linux-mint-or-debian-linux/
:scheme:https
accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
accept-encoding:gzip, deflate, sdch, br
accept-language:en-US,en;q=0.8
cookie:_ga=GA1.2.251051396.1499461219; _gat=1
dnt:1
referer:https://slumpedoverkeyboarddead.com/
upgrade-insecure-requests:1
user-agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36Client-side collection
The server-side information is easily collected, but our old client-side friends JavaScript and Adobe Flash® will betray much more information about your browser. A quick internet search will deliver a number of sites that show how much data your web browser will provide when asked.
For example, I learn from Am I Unique? that my browser will provide a daunting list of information including:
- every font available on my system
- the list of plugins I have installed
- the resolution of my screen
- the language of my system
- whether my browser accepts cookies
- and more.
The entire list of what Am I Unique collects is here, and even more is possible.
The table below is taken from an Am I Unique paper1 published in March of 2016. Note that the two richest areas of data collection are the client-side JavaScript and Adobe Flash®.
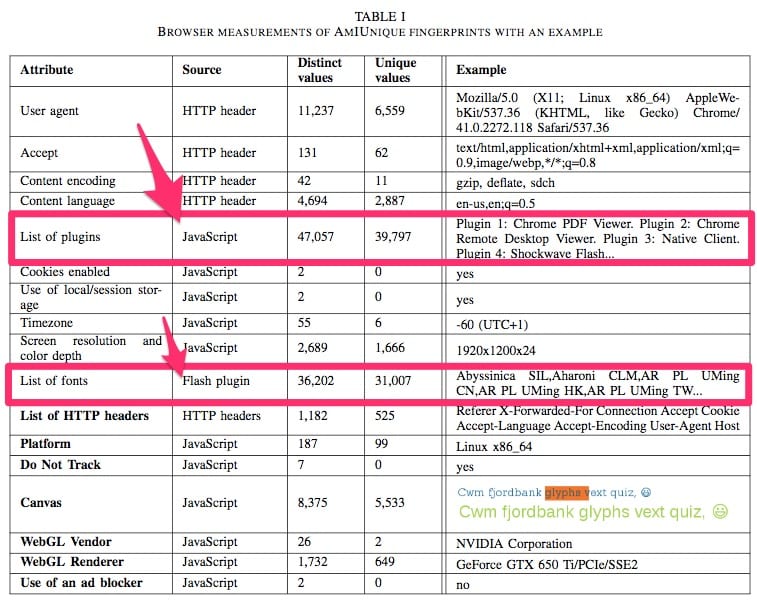
Consider the example above where the server logs showed my IP address, browser, and operating system. Now add in the list of information that JavaScript and Adobe Flash® supply, and you can start to see how easy it would be to correlate visits.
If two visits share exactly the same set of data except for the IP address, for example, it would still be possible to infer that those visits were from the same person. This is an especially useful technique when someone is using a VPN which makes their IP address less useful as an identification point.
When using a VPN, the only data point that changes is the requester’s IP address. Am I Unique shows that it can collect 21 data points, and that’s not even including the three data points from the server logs. Therefore, using a VPN to change one point of data (your IP address) still leaves 23 points of data for comparison.
There is no global standard for human fingerprinting in law enforcement, but certainly, any fingerprint with 23 matching points would be considered hefty evidence.
How does the comparison work?
Most privacy-minded people are of the mindset that the less information you provide, the better your privacy will be. This is true only in a world where you can opt to not do things. For example, if I don’t want to have any personal information on Facebook, then I choose not to use Facebook.
However, it’s virtually impossible to not use the internet at all these days, so you’re going to leave fingerprints behind. Therefore, the goal here is to make it difficult for your private activities to be correlated to your public activities. Maintaining this separation prevents anyone from identifying you, personally, using data from activities you’d like to keep private.
However, using good privacy techniques such as locking down your browser to disallow JavaScript, cookies, and WebRTC requests could make your browser more unique since few people do the same. For example, using the Electronic Frontier Foundation’s Panopticlick, we can see the difference in the two configurations.
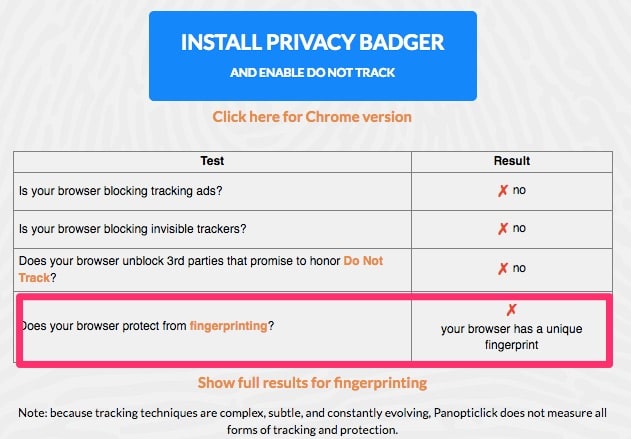
With JavaScript enabled, my browser is easily trackable:
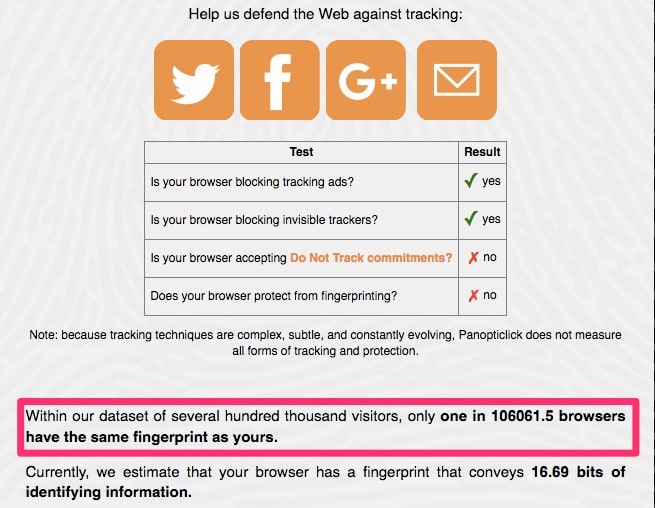
With JavaScript turned off, my browser is still trackable, but it becomes so unique that it only matches one in about 100,000 browsers. When you consider that there are billions of internet users, being one in 100,000 is relatively unique.
It’s important to note that there is really very little fingerprinting data available to test with. While there are a number of sites such as Am I Unique (352,000 records at this time), Panopticlick (470,161 records), and others, they have a relatively small amount of data to work with. As well, it’s likely that most of that data came from privacy-minded users rather than the general internet population, so the stats are probably not very reflective of the average internet user.
The real danger comes from the possibility that sites like Facebook, with 1.86 billion monthly regular users, are compiling massive databases of browser fingerprinting data. When very popular sites like that get in on the action, the specter of invisible internet tracking becomes very real.
The more unique your browser, the easier it is to identify across sites. So, in this case, it doesn’t really pay to lock down your browser. On the other hand, surfing the web with an insecure browser is an extremely risky activity these days. So what’s the best solution?
How to prevent browser fingerprinting
Since there’s no feasible way to safely use the same browser to carry out both your private and public internet activities, the best browser fingerprinting protection right now is to separate those two profiles. Use one system or browser for your day-to-day activities and a separate one for your private activities.
It’s best to go one step further and use an anonymity tool such as Whonix for your private activities to ensure an even larger separation between your private and public profiles. Maintaining this separation will require good operational security.
OpSec (Operational Security)
OpSec is the process of collecting large amounts of available information about someone that seems unrelated at first glance, but can be analyzed to provide some very specific information. A very obvious example is logging in to your Facebook account while using a privacy tool such as Tor. Once you’ve logged in, you’ve confirmed your identity without any need for an adversary to analyze your browser fingerprint.
There is no end to OpSec blunders which can make the correlation of your public and private internet activities easier, but here are some starting points.
- Your private internet activities should never involve using any site that you also use in your public internet life. Account correlation, such as the Facebook example, will cut right through your privacy attempts.
- Your private activities should not include composing messages. This protects against stylometric analysis. If it’s not possible to avoid composing messages, you should seek to change your writing style significantly.
- Use a completely different computer system that is permanently connected to an anonymity tool like Tor or a trusted VPN for your private activities. This helps prevent against inadvertent data leakage such as DNS queries or WebRTC requests.
- If you use a VPN for both your private and public internet activities, connect to a different VPN server for each type of activity. You may also want to use a VPN with Tor, in which case there are some VPNs that work better with Tor than others.
- Do not reuse usernames, email addresses, or any other account information from your public activities within your private activities. This protects against leaving an inadvertent trail of breadcrumbs such as the one that helped identify the owner of the illegal Silk Road marketplace.
Separating your activities like this will not prevent either your public or private activities from being fingerprinted to some degree, but it can prevent the correlation between those two sets of actions. An observer will probably be able to tell that the same person carried out the private activities, but less able to tie that person to your public identity.
What are web browser operators are doing to combat fingerprinting?
It hasn’t escaped the notice of the likes of Google and Mozilla that browser fingerprinting violates user privacy. As such, companies like this promise to take action to prevent certain data collection.
For example, Google proposes that its Privacy Sandbox initiative will include a “privacy budget” that essentially limits the number of API calls websites can make. However, this is not yet in place.
Mozilla Firefox is ahead of the game and already blocks canvas fingerprinting attempts, starting with version 58 released back in 2018. When websites want to extract canvas data, they need to ask permission from users first.
That said, Firefox wasn’t the first browser to block canvas fingerprinting and the Tor browser has been requesting user permission for such data collection since 2013.
Both Tor and Firefox also employ select anti-fingerprinting techniques such as “letterboxing.” When you maximize the window containing your web browser, the site you’re visiting can use your monitor dimensions as an identifying feature. Letterboxing essentially masks your monitor’s true dimensions with generic sizes, such that this piece of information is no longer useful as an identifying factor.
Browser fingerprinting and the GDPR
The GDPR never mentions browser fingerprinting explicitly, but this is intentional; legislators have learned from past experience to keep rules neutral of any specific technology. The ePrivacy Regulation, on the other hand, does explicitly mention device fingerprints.
Instead, the GDPR simply defines personal data as any information that might be linked to an identifiable individual. This includes identifiers such as cookies, IP addresses, advertising IDs, and, yes, fingerprinting. The Electronic Frontier Foundation explains that identification doesn’t necessarily mean discovering a user’s identity:
“It is enough that an entity processing data can indirectly identify a user, based on pseudonymous data, in order to perform certain actions based on such identification (for instance, to present different ads to different users, based on their profiles). This is what EU authorities refer to as singling-out, linkability, or inference.”
The GDPR states any entity that processes personal data must prove they have a legitimate reason to do. Furthermore, the ePrivacy Regulation that came into effect in 2019 requires that websites and apps gain users’ opt-in consent before tracking them. On top of that, businesses that fingerprint must allow users to see what information they collect as well as its scope, purpose, and legal basis.
1. “Browser measurements of AmIUnique fingerprints with an example”. Pierre Laperdrix, Walter Rudametkin, Benoit Baudry. Beauty and the Beast: Diverting modern web browsers to build unique browser fingerprints. 37th IEEE Symposium on Security and Privacy (S&P 2016), May 2016, San Jose, United States.






{kind=link}
good article, thanks. sites are increasingly using canvas fingerprinting to deny access to their content based on iding the requesting computer/system. some browsers are more vulnerable than others. these sites admins are anti-internet-against the original intent and values of the net and deserve to be blacklisted in turn.