

In this report, you will learn how to simplify your server monitoring duties and how to break down the important tasks to make them manageable. We’re going to look at the following monitoring categories:
- Server availability
- Server utilization
- Physical properties
Once you establish a routine, monitoring tasks become very straightforward. You just need to know where to start.
Server availability
No matter whether your server has lots of spare capacity or you are pushing its limits, the only thing that the user community cares about is that it is available. The worst performance issue the server will experience is you taking it offline.
In order to keep the server running at its top performance, you are going to need to take it offline from time to time. You will need to perform system cleaning tasks, such as defragmenting the disk, removing temporary files, and reallocating resources, such as storage space, or VM configurations.
Set your monitoring strategy so that you get advanced warning of capacity limits being reached. These will give you the option of performing remedial action, such as creating more disk space ahead of time rather than at the last minute when users need access to the server.
The operating system will need to be patched from time to time and many software packages will need to be updated. So, plan all maintenance tasks for out-of-hour periods. That doesn’t mean that you need to sit up all night because most standard maintenance tasks can be scheduled to run in the small hours of the morning. Be careful to check that there are no essential business batch jobs scheduled for the times that you hope to bounce the server.
One metric that a monitoring utility can give you about server availability is called Uptime. This will show you how long the server has been available and should tally with your own calculations of the time elapsed since you rebooted it. If it doesn’t, then the server failed at some point. The problem with this metric is that you only get to know that the server went down when it is too late. In truth, you probably would have known about an unexpected outage if it happened during business hours because your phone would have started ringing off the hook. However, investigations into why the server went down unexpectedly will enable you to take preventative measures to stop it from happening again.
Server utilization
Your main daytime tasks for server performance monitoring revolve around watching a shortlist of performance issues. These are:
- Processing capacity and utilization
- Memory capacity and utilization
- Disk capacity and occupied space
- Page faults
- Page swapping
- Network interface (I/O) activity
Initially, there is little you can do about these issues other than sit and watch. If you weren’t responsible for buying the server and you weren’t involved in defining the requirements for it, then the best way to work out whether the equipment is fit for purpose is to record its activities and note whether its limitations actually get reached.
In this respect, your monitoring activities will always feed into systems management issues. If you spot performance problems, you will be expected to do something about them.
CPU, memory, and disk performance
The processor has a finite capacity and if that isn’t enough for all of the services and software that it needs to run simultaneously then performance will take a hit. The same is true for RAM and disk space.
It is better to head off full capacity by setting threshold warning levels where CPU, memory, and/or disk space is within reach of being exhausted. That buys you time to take action to head off performance impairment. Discussion of those actions is out of scope for this guide but briefly, you will need to kill a process that seems to be hanging – waiting for resources, or blocking other processes from running. You can also consider moving some services to other servers if you have them.
Page faults
Page faults are particularly important if you use cloud-based servers, such as AWS, Google Cloud Platform, or Azure. These virtual servers use a “page” concept, which is a block of memory. Basically, the page is the portion of physical memory that has been allocated to your company’s account, or “virtual server.”
A page fault occurs when memory addressing problems arise. This should never happen, but it does. Generally, as this is a service problem, it isn’t your fault and it isn’t your job to fix it. However, you need to know about page faults because they slow down response times. The server will have its own routines to recover from page faults and the cloud service’s technicians will be onto it.
Despite the fact that memory paging is an automated system that should never go wrong, page faults will occur from time to time. If the number of page faults starts to rise, there is a serious problem that could overload the server’s fault handler. If this happens then the performance of your virtual server will be noticeably impaired and users will start to complain.
Page swapping
Servers acquire disk space if memory is running out. This process is called “page swapping.” The memory manager will store some data temporarily on the disk, recalling it when needed.
If you notice that disk space has reduced and memory is fully occupied, this phenomenon might be due to page swapping. Check on this metric to see if that’s what is going on.
Page swapping in itself is not bad. However, the server takes longer to process data stored in temporary files on the disk than it does to get data directly from memory. This means that the occurrence of page swapping will slow down server response times.
It is a good idea to have page swapping enabled as an emergency measure. However, if swapping starts to be a frequent event, you should increase the RAM available in your hardware.
Network interfaces
Much of the issues related to I/O monitoring push into the topic of network monitoring, which is a separate issue. However, looking at activity on your network card could be a server problem if the network interface gets overloaded – which means that not all requests are getting through. Overloading could also be an indication of a malicious attack or, it could mean that the card is impaired in some way or not fit for the purpose and you might need to replace it. If network interface activity goes down to zero, your card is probably broken.
Physical properties
A couple of other factors that you need to watch on your server include physical attributes:
- Temperature
- Fan speed
- Power supply
- Physical access
As the systems administrator, you are responsible for the server, and that includes monitoring its physical health.
Physical access
The issue of physical access might not seem to be a performance monitoring issue. However, if a malicious intruder gets into your server room, then the availability of the server could be threatened. As explained above, a server going offline is the biggest performance issue that you need to prevent. So, monitor and control access to the server room.
Temperature and fan speed
Temperature and fan speed are interrelated issues. It is probable that you won’t be able to turn a dial and speed up the fan when you see that the server’s temperature is rising. However, watching your server’s temperature will give you time to check on any physical problems with the fan. You may need to check the server room temperature. If the fan is drawing in warm air, it won’t help to cool down the server.
Certain applications, such as databases and web servers create a lot of load on a processor and so generate more heat. Consider distributing these applications to different servers to lower the load and the temperature. Also, look into the usage of a rack; using every slot might be blocking the circulation of cool air.
Power supply
Power supply monitoring is a given – you don’t want the voltage to surge or drop. Your UPS should take care of that problem, but you need to monitor current and voltage coming out of that and into your server to be sure that the UPS is working properly.
Monitoring tools
You can check on all of the important metrics outlined above with command-line utilities and operating system GUI interfaces. However, repeatedly running commands and checking on process monitoring utilities is very time-consuming.
It is better to buy software that will monitor the server for you. Typically, server monitoring software keeps a constant check on those vital indicators and alerts the system administrator if one of the pre-set thresholds gets breached. This enables you to get on with other tasks. You can assume that everything is okay unless you are notified otherwise.
There are many very good monitoring tools available on the market today. It is very common for server monitoring systems to be combined with other functions. The number one monitoring combination that you will encounter is the server and applications monitor. This is because server performance is very closely tied to the performance and requirements of applications.
Site24x7 Server Monitoring (FREE TRIAL)
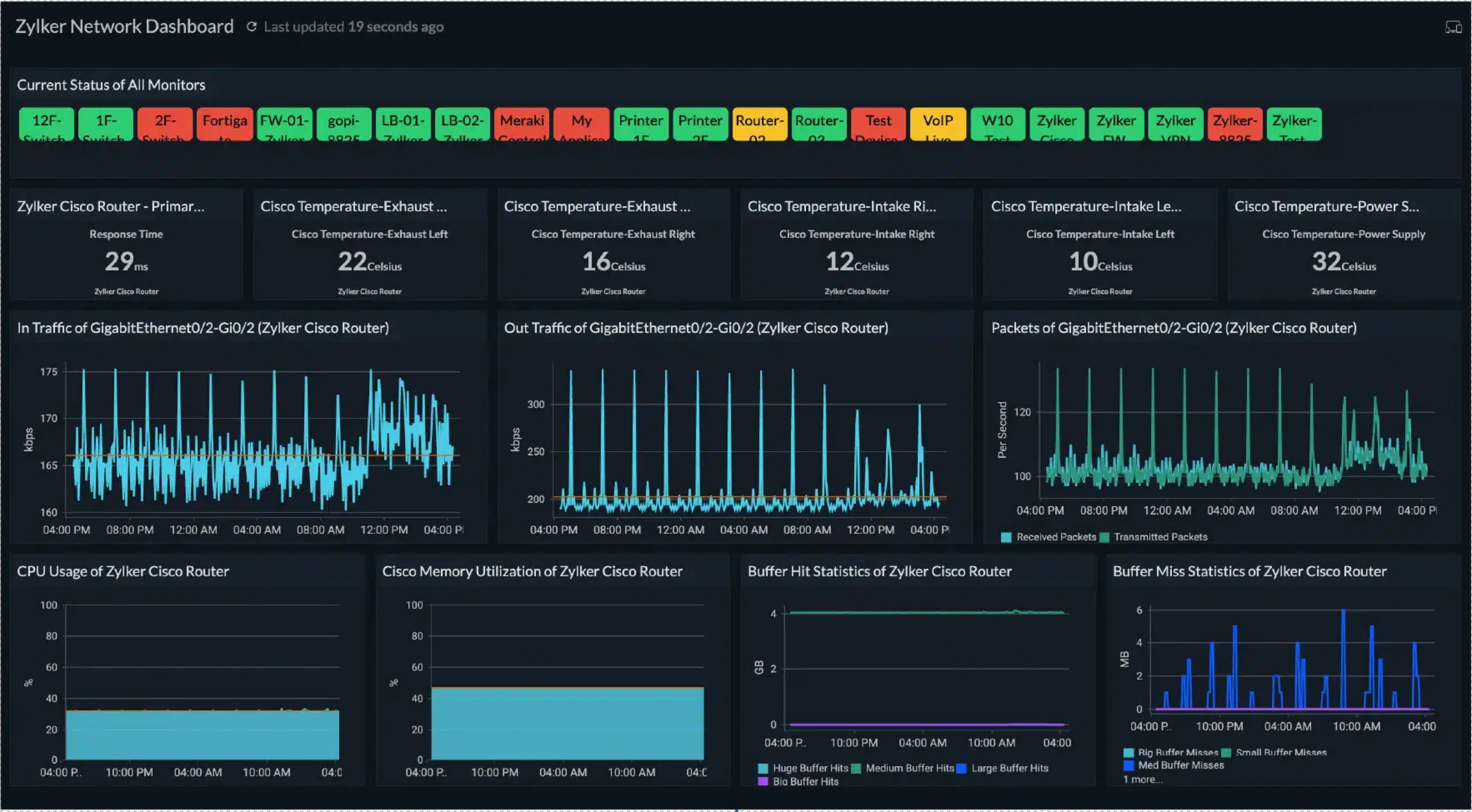
Site24x7 Server Monitoring is a cloud-based SaaS module that gathers activity data about servers and measures capacity utilization for key resources. This package focuses on CPU, memory, and disk space availability and can also track virtual server activity down to supporting physical server resources.
Key Features:
- Monitors endpoints running Windows or Linux
- Expansion library to monitor specific technologies
- VMware and Hyper-V monitoring
- Watches processor queue length
Why do we recommend it?
The Site24x7 Server Monitoring service monitors physical and virtual servers. It is able to track activities on hosts running Windows or Linux and also on cloud servers provided by Azure and AWS. The system will also track virtualizations formed with Hyper-V or VMware and can record container activity run through Kubernetes and Docker.
The dashboard for the Site24x7 system is hosted in the cloud and can be accessed through any standard Web browser. The metrics that are uploaded to the Site24x7 server by an on-site agent are displayed in tables and graphs. The screens offer an overview of all enrolled servers and their statuses with a drill-down function that gives access to details of a particular server. The screens in the dashboard can be customized, enabling the user to mix graphs and data provided by different modules into one view.
The Site24x7 package includes a network monitoring section, which includes a discovery service. This system scans the network and logs all of the equipment connected to it. That includes servers and workstations. The discovery process creates an IT asset inventory, which the Server Monitoring unit accesses.
Each system monitored by the Site24x7 package has a performance expectation placed against it. For example, it is known how much CPU capacity a server has and if that resource is approaching full capacity, a problem might be about to occur. The performance expectations are expressed in the form of thresholds and if they are crossed, the system will raise an alert. It is also possible to attach automated processes to an alert.
Alerts are listed in the Site24x7 dashboard with a severity rating and the monitor can be set up to forward alerts to specific technicians as notifications by email, SMS, voice mail, or Slack message.
The Server Monitoring system is able to unify the monitoring of hosts that are on different sites and the overview screen can include a summary of the performance of computers that have different operating systems.
Who is it recommended for?
Companies that don’t want to have to host the applications that they use would not be interested in the SolarWinds service that is explained above. The Siyte24x7 package is a good cloud-based alternative. The plans of Site24x7 are available in a base edition for small businesses with capacity expansions for larger businesses.
Pros:
- Tracks CPU, memory, and disk capacity and utilization
- Part of a package that provides full-stack observability and root cause analysis
- Metrics storage for long-term capacity planning
- Alerts that can trigger automated remediation actions
Cons:
- No on-premises version
The Server Monitoring module is included in all of the many Site24x7 plans. There is an MSP edition for managed service providers. You can assess the Site24x7 platform with a 30-day free trial.
ManageEngine OpManager (FREE TRIAL)

ManageEngine OpManager monitors servers through agents and agentless mechanisms. It scans your networks, identifies servers, and automatically classifies them based on their type, vendor, functionality, location, and more. Also, it monitors these servers continuously to ensure they are available and performing optimally.
Key Features:
- Uses ICMP, SNMP, and TCP protocols to check your servers’ availability.
- Enables you to customize monitoring settings.
- Tracks KPIs.
- Provides a visualization of server arrays and datacenters.
- Automates incident response to resolve issues.
Why do we recommend it?
We recommend OpManager due to its advanced features that help you maintain high uptime, performance, and resilience for your servers. It tracks over 300 metrics related to server performance and compares them with existing thresholds. In case of deviations, it sends alerts, so your team can fix the issue right away.
It even provides automated remediation and the first level of troubleshooting to prevent any issues from impacting your critical processes and operations. One of our favorite aspects is that OpManager offers more than 70 actions, and all that you have to do is drag and drop these actions on a workflow for immediate automation. This requires no coding knowledge, just a comprehensive idea of the systems and the required actions.
Another key aspect of this tool is that it supports multiple environments. It can be used for Windows, Linux, virtual, Exchange, database, and domain controllers.
Who is it recommended for?
OpManager works well for organizations with multiple server environments. It is also ideal for medium to large organizations with a mix of physical and virtual servers, and for MSPs looking for automated remediation.
Pros:
- Comprehensive metrics, covering all aspects of server performance.
- Support for multiple platforms.
- Automated remediation and troubleshooting.
- Sends instant alerts to prevent server hardware failures.
Cons:
- Setup is complex.
OpManager offers Standard and Professional editions, each with an annual subscription and perpetual licensing options. It also offers many add-ons based on your organization’s needs. Start a 30-day free trial.
Security monitoring can also be combined with server management functions.
Implementing server monitoring
The easiest way to monitor your servers successfully is to get an automated tool to do the job for you. This strategy works out cheaper than hiring extra staff to perform the task manually.
Server monitoring automation, based around earning thresholds can be adjusted according to your own working practices and solution lead times. These tools can also be used to predict future requirements. That will enable you to buy expansion hardware and make sure that server performance stays sufficient to keep the user community happy.
