
Unless you’re dedicated to keeping up with the latest in artificial intelligence, you may have never heard the term ‘federated learning’ before. Although it may not be as prominent as other tech trends like 3D printing or drones, its implications for privacy and machine learning could lead to much greater usage in the coming years.
The short and simple version is that federated learning is an alternative model for improving the algorithms that now dominate many aspects of our life, whether they be Facebook’s News Feed or Google Maps. Under the more traditional system, our data is sent to a central server where it is analyzed, and the relevant information is used to alter the algorithm.
Federated learning offers a solution that enhances user privacy because the majority of personal data stays on a person’s device. Algorithms train themselves directly on user devices and only send back the relevant data summaries, rather than the data as a whole. This allows companies to improve their algorithms without needing to collect all of a user’s data, providing a more privacy-focused solution.
What is federated learning?
Let’s not lie, for most people, the depths of federated learning can seem complex and difficult to understand. The field of AI is far outside the realm of many peoples’ knowledge and involves way more math and logic than most of us are comfortable with.
Despite these difficulties, federated learning is an interesting and important tech development, so it’s worth trying to get your head around it. To make things easy, we will break down the concepts and explain them in a simplified manner so that you can understand the big picture.
Machine learning and algorithms
Unless you spend your days cosplaying the 1930s, your life is filled with algorithms. In this context, when we refer to algorithms, we essentially mean formulas or sets of instructions that are used to figure out a problem or compute a desired result.
Facebook, Instagram and Twitter use them to deliver personalized content that is most likely to interest you, as well as make the platforms more money. Google’s search engine uses sophisticated algorithms to turn your search terms into pages of what it thinks you are looking for. Your email filters out spam with algorithms, while Waze leverages algorithms to figure out the most effective way to get from point A to point B.
There are countless other algorithms that help us complete tasks, keep us occupied or lurk under the hood of everyday processes.
Companies are constantly trying to improve these algorithms to give you the most effective, accurate and efficient results, as long as that aligns with the company’s own objectives – usually making money.
Many of our most-used algorithms have come a long way since their initial deployment. Think back to searching through Google in the late nineties or early 2000s – you had to be incredibly specific, and the results were terrible compared to the present day.
So how do these algorithms improve?
A major part of how algorithms get better at their tasks involves machine learning, which is a subfield of artificial intelligence. Machine learning algorithms start by taking a sample of data, analyzing it, then using what they have learned to accomplish tasks more effectively. They are able to improve without needing to have these changes programmed in by an outside force, such as a human developer.
Machine learning has been booming in the last few decades, improving our algorithms, helping us get better results and moving into new fields. Because of its utility, it has also been a huge money-maker for companies like Facebook, Google and many others.
It all starts with data – the larger the data pool, and the greater the number of high-quality data points, the more accurate these machine learning algorithms can be. The more effective an algorithm is, the more money it can make, which has essentially turned data into a commodity.
These conditions have caused a massive expansion in the amount of data that is collected on people. For the most part, this data is collected from users’ phones, computers and other areas, then sent to a server where it is analyzed to improve the algorithm. While this has often led to better services and increased convenience, there has also been a significant pushback from those who are worried about their privacy.
There is something sinister about these companies knowing your location at all times, knowing who you’re friends with, knowing your entire search history and much, much more. Sure, there are ways to avoid these types of data collection, but the techniques are generally too impractical for most people to bother.
Amid a series of data privacy scandals, like Facebook’s Cambridge Analytica fiasco and Google+’s massive data breach, companies have begun to take notice. Not wanting to be usurped, they seem to be looking at avenues to continue advancing their goals without raising the ire of their users or legislators. Perhaps the watershed moment was when Mark Zuckerberg announced that “The future is private,” at this year’s F8 conference.
While it’s probably best to look at this movement with skepticism, there have been some positive developments with regards to user privacy, one of which is federated learning.
Federated learning
Instead of taking data from user devices to our server, why don’t we send the algorithm to the data?
This is the core concept behind federated learning. The term was coined in a 2016 paper published by Google employees, and the company has remained at the forefront of the field.
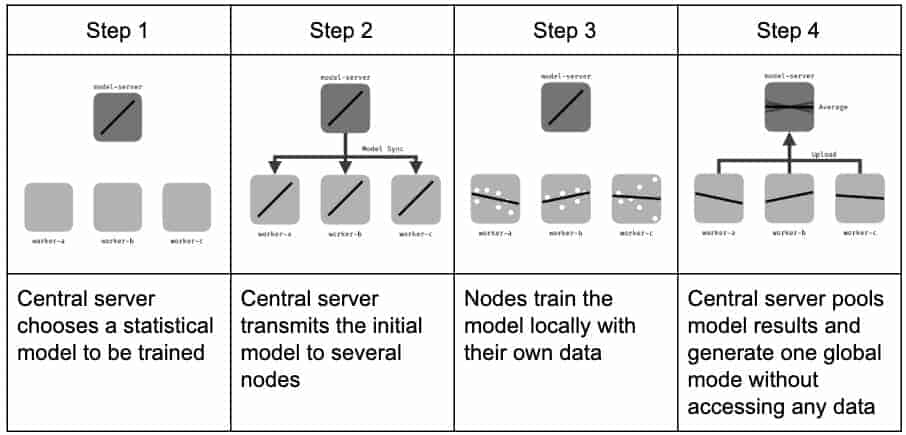
The federated learning training process.
Federated learning improves algorithms by sending out the current version of an algorithm to eligible devices. This model of the algorithm then learns from the private data on the phones of a select group of users. When it finishes, a summary of the new knowledge gets sent back to the company’s server – the data itself never leaves the phone.
For security, this knowledge is generally encrypted on its way back to the server. To stop the server from being able to figure out individual data based on the summary it has received, Google has developed the Secure Aggregation protocol.
This protocol uses cryptography to prevent the server from accessing the individual information summaries. Under this scheme, the server can only access the summary after it has been added to and averaged with the results from hundreds or thousands of other users.
Alternatively, differential privacy can be used to add random data noise to an individual’s summary, obscuring the results. This random data is added before the summary is sent to the server, giving the server a result that is accurate enough for algorithmic training, without the actual summary data being revealed to it. This preserves the individual’s privacy.
Techniques like the Secure Aggregation protocol and differential privacy are crucial for protecting user information from both the organization and hackers. Without them, federated learning could not ensure the privacy of users.
Once the information summaries have been safely sent to the server, they are used to update the algorithm. The process is repeated thousands of times, and test versions of the algorithm are also sent out to various user devices. This allows organizations to evaluate new versions of algorithms on real user data. Because analysis is performed from within the confines of user devices, algorithms can be trialed without having to pool user data on a central server.
When the tests are completed, the updated algorithm model is sent to user devices to replace the old one. The enhanced algorithm is then used in its normal tasks. If everything has gone according to plan, it will be more effective and accurate at achieving its results.
The whole cycle then repeats itself over and over again:
- The new algorithm studies the data on selected user devices.
- It securely sends summaries of this user data to the server.
- This data is then averaged with results from other users.
- The algorithm learns from this information, produces updates and tests them.
- A more advanced version of the algorithm is pushed out to users.
Over time, the algorithm learns from user data and continually improves, without ever having to store the data on company servers. If you’re still struggling to wrap your head around what federated learning is and how it works, Google published this cartoon that explains and helps you to visualize the federated learning approach in a simple manner.
Other advantages of federated learning
The federated learning model offers users several other benefits on top of privacy. Instead of continually sharing data with the server, the learning process can be conducted when a device is charging, connected to wifi and not in use, minimizing the inconveniences faced by users.
This means that users aren’t wasting their precious data or battery when they are out and about. Because federated learning only transfers a summary of relevant data, rather than the data itself, the process ends up transferring less data overall than under traditional learning models.
Federated learning can also deliver both global and personalized algorithmic models. It can glean insights from a broader group of users and combine them with information from the individual user to deliver a more effective model that suits their unique needs.
Applications of federated learning
Federated learning has a wide array of potential use cases, especially in situations where privacy issues intersect with the need to improve algorithms. At the moment, the most prominent federated learning projects have been conducted on smartphones, but the same techniques can be applied to computers and IoT devices like autonomous vehicles.
Some of the existing and potential uses include:
Google Gboard
The first large-scale deployment of federated learning in the real world was as part of Google’s keyboard application, Gboard. The company aimed to use the technique to improve word suggestions without compromising user privacy.
Under the old machine learning approach, developing better keyboard predictions would have been tremendously invasive – everything we typed, all of our private messages and strange Google searches would have to have been sent to a central server for analysis, and who knows what else the data could have been used for.
Thankfully, Google chose to use their federated learning approach instead. Because the algorithmic model is placed on user devices, it is able to learn from the words that users type in, summarize the key information and then send it back to the server. These summaries are then used to enhance Google’s predictive text feature, which is then tested and pushed out to users.
The new version of the algorithm will offer an improved experience thanks to what it has learned from the process, and the cycle repeats itself. This enables users to have continually improving keyboard suggestions, without having to compromise their privacy.
Healthcare
Data privacy and security are incredibly complex in the healthcare industry. Many organizations harbor significant amounts of both sensitive and valuable patient data, which is also keenly sought after by hackers.
No one wants an embarrassing diagnosis leaked to the public. The wealth of data contained in these repositories is tremendously useful for scams like identity theft and insurance fraud. Because of the large amounts of data and the huge risks faced by the health industry, most countries have implemented strict laws about how health data should be managed, such as the US’s HIPAA regulations.
These laws are quite restrictive and come with significant penalties if an organization violates them. This is generally a good thing for patients who are worried about their data being mishandled. However, these types of legislation also make it difficult to use some forms of data in studies that could help with new medical breakthroughs.
Because of this complex legal situation, organizations such as Owkin and Intel are researching how federated learning could be leveraged to protect the privacy of patients while also putting the data to use.
Owkin is working on a platform that uses federated learning to protect patient data in experiments that determine drug toxicity, predict disease evolution and also estimate survival rates for rare types of cancer.
In 2018, Intel partnered with the University of Pennsylvania’s Center for Biomedical Image Computing and Analytics to demonstrate how federated learning could be applied to medical imaging as a proof of concept.
The collaboration revealed that under a federated learning approach, their particular deep learning model could be trained to be 99 percent as accurate as the same model trained through traditional methods.
Autonomous vehicles
Federated learning could be useful for self-driving vehicles in two major ways. The first is that it could protect the privacy of user data – many people dislike the idea of their travel records and other driving information being uploaded and analyzed on a central server. Federated learning could enhance user privacy by only updating the algorithms with summaries of this data, rather than all of the user information.
The other key reason for adopting a federated learning approach is that it can potentially reduce latency. In a likely future scenario where there are a large number of self-driving cars on our roads, they will need to be able to rapidly respond to each other during safety incidents.
Traditional cloud-learning involves large data transfers and a slower learning pace, so there is the potential that federated learning could allow autonomous vehicles to act more rapidly and accurately, reducing accidents and boosting safety.
Complying with regulation
Federated learning may also help organizations improve their algorithmic models without exposing patient data or ending up on the wrong side of regulations. Laws, such as Europe’s General Data Protection Regulation (GDPR) and the US’ Health Insurance Portability Act of 1996, have strict regulations over the data of individuals and how it can be used.
These laws are generally in place to protect the privacy of individuals, which means that federated learning could potentially open up new opportunities by being able to learn from the data while still keeping it safe and within the regulatory guidelines.
The security and privacy of federated learning
Federated learning opens up a world of new opportunities for training machine learning models without compromising data privacy. However, it needs to be implemented carefully to mitigate security issues and the possibility of exposing user data.
Some of the main problems, as well as their potential solutions, include:
Interception of user data summaries
Providing adequate privacy and security generally involves a combination of different technologies as well as policy. While federated learning gives us new ways to protect data, it still needs to be implemented alongside complementary mechanisms.
One example of a potential weak point is that when data summaries of users are sent from the device to the central server, they could be intercepted by hackers who could use them to figure out the original data.
Thankfully, this problem has a relatively straightforward solution that we already implement in many areas of information security – we simply need to encrypt the data with the appropriate algorithm as it travels between the two points.
Figuring out the original data from user summaries
In certain scenarios, the user data summaries can be used to determine the original information. If a malicious party sends queries to the model through the API, it may be possible to reconstruct the data, although this isn’t a unique problem to federated learning.
If attackers or the organizations that own the servers could figure out the original user data in this manner, it would completely defeat the purpose of implementing federated learning. There are two key mechanisms that can be deployed alongside federated learning to prevent this from occurring: Google’s Secure Aggregation protocol and differential privacy.
The Secure Aggregation protocol uses multi-party computation to calculate the average of a group of user data summaries, without revealing the data summaries of any single individual to the server or any other party.
Under this system, each of the user summaries are encrypted before they leave the user’s device, and they cannot be decrypted by the server until they have been added together and averaged with a set number of other user summaries. This allows the server to train its model on the user average, without exposing individual summaries that could be used to uncover an individual’s private data.
Not only does Secure Aggregation prevent the server from accessing the user summaries, but it also makes man-in-the-middle attacks much more difficult.
The other option is differential privacy, which includes a variety of related techniques that involve a specific amount of noise being added to data. The main premise of differential privacy is that for a user’s data to remain private, queries to the database should not reveal whether an individual was included in the data, nor what their information was.
To prevent queries from revealing this information, several different options can be used to add noise to the data. This data noise is added before it leaves a user’s device, preventing both the server and attackers from accessing the updates in their original form.
Model poisoning
Federated learning opens up the opportunity for adversaries to “poison” the algorithmic model. Essentially, this means that a malicious actor can corrupt the model through their own device, or by taking over the devices of other parties involved in training the algorithmic model.
These attacks were explored in detail by Bagdasaryan et al. in their How to backdoor federated learning paper. Under a federated learning model, the attacker has the potential to take over one or more participants.
In certain scenarios, it’s possible for them to control the data of each participant they have taken over, to alter how that data is trained locally, to change the hyperparameters such as the learning rate and the weighting of the individual model (before it is submitted to the server for aggregation). It’s also possible to change each participant’s approach to local training from one round to another.
With these abilities, attackers can inject backdoors that can modify algorithms toward their own aims. According to figures from the study, poisoning the model was far more effective than other data poisoning attacks.
In a word-prediction task involving 80,000 participants, the researchers could achieve 50 percent backdoor accuracy by compromising just eight of the participants. To accomplish the same effect by poisoning the data, the researchers would have had to compromise 400 participants.
One of the biggest issues comes from the fact that federated learning and the Secure Aggregation protocol aim to keep user data private. When implemented correctly, this makes it impossible for the server to detect anomalies in an individual user’s summaries.
As we mentioned above, the Secure Aggregation protocol only allows access to user summaries once they have been added together with other user data. Because summaries can’t be screened individually, this makes it impossible to see anomalies that may lie within them, giving model poisoning attacks the perfect way to sneak in.
At this stage, these attacks and their possible defenses need to be researched more thoroughly.
Keeping the model private
Sophisticated algorithmic models can be worth millions, which makes them a target for thieves. They can use them to make money in the same way that the companies behind the algorithms do, or even leverage them for illicit purposes. Not only would it save the thieves from investing the tremendous amounts of funding into building the model, but it could also devalue the original.
Companies need to protect their intellectual property, and it seems like sending the model directly to the devices of users could easily result in these models being exposed to anyone who wants to take them. However, there are solutions that companies can use to protect their algorithmic models.
One of these is to leverage the secret sharing of multi-party computation. This allows organizations to conceal the model weighting by distributing fragments of it across devices. Under this system, none of the secret-holding parties can know the entire model.
This allows organizations to push their algorithmic training models to devices without having to worry about having their intellectual property stolen.
Limitations of federated learning
In addition to the potential security issues, federated learning has a number of other limitations that prevent it from being a magic pill to solve all our data privacy issues.
One consideration is that when compared to traditional machine learning methods, federated learning requires significantly more local device power and memory to train the model. However, many new devices have ample power for these functions, and this approach also results in a much smaller amount of data being transferred to central servers, reducing data usage. Many users may find this trade-off beneficial, as long as their device is powerful enough.
Another technical issue involves bandwidth. Federated learning is conducted over wifi or 4G, while traditional machine learning occurs in data centers. The bandwidth rates of wifi or 4G are magnitudes lower than those used between the working nodes and servers in these centers.
Bandwidth to devices hasn’t grown as rapidly as their computation power over the years, so insufficient bandwidth could potentially cause a bottleneck that increases latency and makes the learning process slower when compared to the traditional approach.
If algorithm training is conducted while a device is in use, it reduces a device’s performance. Google has gotten around this problem by only training devices when they are idling, switched on and plugged into an outlet. While this solves the problem, it slows down the learning cycle, because training can only be done at off-peak times.
A further challenge is that devices drop out during the training process – they may be put to use by their owners, turned off, or undergo some other disruption. The data of devices that drop out may not be able to be used properly, which could lead to a less accurate algorithmic model.
Is federated learning the new way forward for machine learning?
Federated learning is a relatively new training model and it shows potential in a number of different applications. Because it’s still in the relatively early stages of study, the process needs much more research before all of its possible uses can be determined, as well as the potential security and privacy risks that it faces.
Until then, it’s hard to say with certainty just how widely the approach will be implemented in the future. The good news is that we have already seen it deployed effectively in the real world with Google’s Gboard.
However, due to some of the previously discussed limitations, it’s unlikely for federated learning to replace traditional learning models in all scenarios. The future will also depend on just how committed to privacy our major tech companies really are. At this stage, we have good reason to be skeptical.