

Fog computing, often referred to as edge computing, is a distributed computing approach that processes, stores, and analyses data closer to where it is generated rather than relying solely on centralised cloud servers. By moving computation to the network edge, it helps reduce latency and improve overall system responsiveness while easing pressure on core cloud infrastructure.
This model is especially valuable in environments where real-time or near-real-time processing is required, such as IoT systems, smart cities, autonomous vehicles, and industrial automation. By handling data locally or near-locally, fog computing enables faster decision-making, improved scalability, and more efficient use of network bandwidth when dealing with large volumes of connected device data.
Compared to traditional cloud computing, fog computing offers advantages in performance, security, and efficiency. Keeping data closer to its source can reduce exposure during transmission, while also lowering network congestion and improving response times. It also helps overcome some limitations of centralised cloud models, particularly in latency-sensitive or data-intensive use cases.
In this article, we will explore fog computing in more detail, including its core characteristics, real-world applications, and the industries where it is most widely used. We will also look at how it supports digital transformation and enhances the performance of IoT and other connected technologies in modern IT environments.
Defogging the concept of fog computing
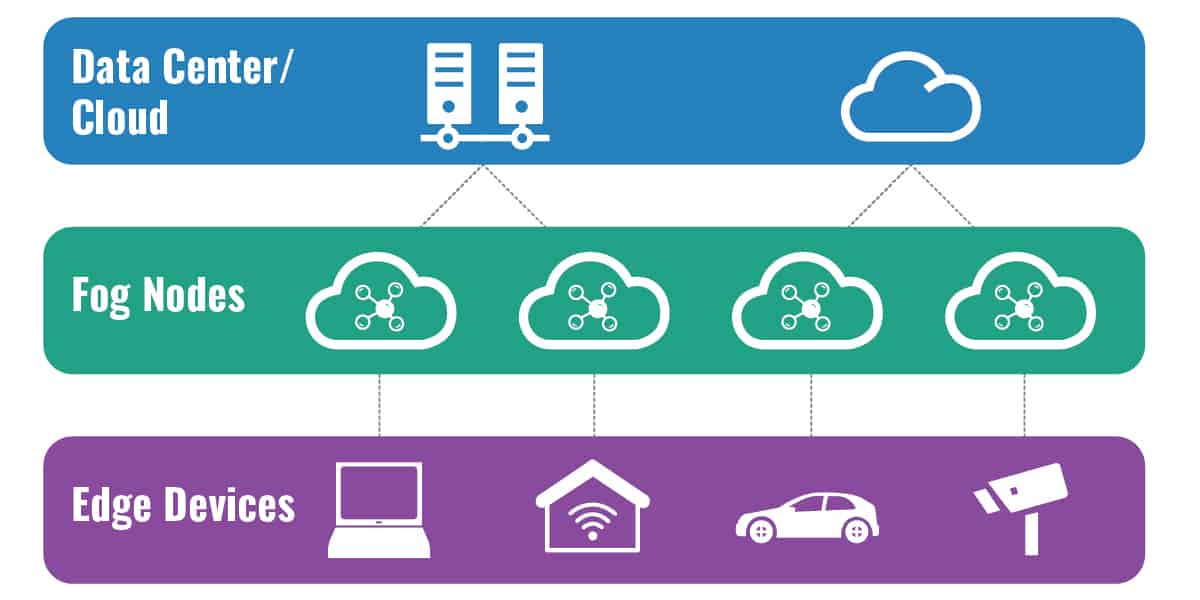
Fog computing refers to decentralizing a computing infrastructure by extending the cloud through the placement of nodes strategically between the cloud and edge devices. This puts data, compute, storage, and applications nearer to the user or IoT device where the data needs processing, thus creating a fog outside the centralized cloud and reducing the data transfer times necessary to process data. The term “fog computing” was coined by Cisco in 2014, and the word “fog” was used to connote the idea of bringing the cloud nearer to the ground—as in low-lying clouds.
Fog computing architecture uses near-user edge devices to carry out substantial amounts of local computation (rather than relying on cloud-based computation), storage (rather than storing primarily in cloud data centers), and communication (rather than routing over the internet backbone). Data is routed over the internet backbone only when necessary. Fog computing is not a replacement for cloud computing; rather it works in conjunction with cloud computing, optimizing the use of available resources. In cloud computing, data is sent directly to a central cloud server, usually located far away from the source of data, where it is then processed and analyzed. Table 1.0 below compares cloud and fog computing.
Many near-user edge devices (such as sensors and IoT devices) generate voluminous raw data, and rather than forward them to cloud-based servers to be processed, the idea behind fog computing is to do as much processing as possible using the computing power of the data-generating devices. Therefore, processed rather than raw data gets forwarded to the server, and bandwidth requirements are reduced.
For example, before the advent of fog computing, we had dumb surveillance cameras that were constantly streaming video data back to the DVR (read server) 24/7, and the server decides what to do with it. But as we start to install many more surveillance cameras, there is so much data coming back to the server. Today, dumb surveillance cameras that transmit video 24/7 to a server, are giving way to the intelligent facial recognition surveillance camera (smart surveillance cameras) that only transmits video when it senses and captures human faces. The captured facial portion of the images is cropped, resized, and sent to a nearby server located within the LAN for analysis. The Server detects the face and sends the response in less than a second. Because of the time-sensitive nature of the response, the data is sent to a local server, instead of a cloud-based server for quick analysis.
That’s a simple example of what it means to put intelligence on the edge of the network. This allows you to be able to put many more devices (smart cameras) on the network without having so much load on your systems. So by pushing that intelligence to the edge, the devices themselves can decide when to send data to the server and this eliminates unnecessary congestion and delays. That in a nutshell is what fog computing is all about.
| Properties | Fog Computing | Cloud Computing |
|---|---|---|
| Type of Service | Localized information | Global information |
Type of connectivity | Wireless link such as WiFi, 4G, ZigBee, etc | Dedicated link |
Geographical distribution | Decentralized and distributed | Centralized |
| Distance between client and server | Single hop | Multiple hops |
| Number of server nodes | A large number of server nodes | A fewer number of server nodes |
| Location of servers | Edge nodes | Cloud servers |
Location awareness | Yes | No |
| Bandwidth consumption | less | More |
| Target user | Mobile users | Internet users |
| Response time | Milliseconds | Minutes |
| Latency | Low | High |
| Work environment | Indoor or remote outdoor locations | Secure data center building |
| Network QoS | Requires strong network connectivity | Can work with the weak network core |
| Security | More secure | Less secure |
Fog computing Vs Edge computing
Fog and edge computing offer similar functionalities in terms of pushing intelligence and data to nearby edge devices. Sometimes the two terms are used interchangeably. However, edge computing is a subset of fog computing and refers just to data being processed close to where it is generated. Fog computing encompasses not just edge processing, but also the network connections needed to bring that data from the edge to its final destination. Think of fog computing as the way data is processed from where it is generated to where it will be stored.
Both technologies leverage the power of computing capabilities within a local network to perform computation tasks. The philosophy of fog and edge computing is to move processing activity closer to the network edge to speed up service. Though they both have the intention of reducing latency and network congestion, they differ significantly in how they actually handle data. The key distinguishing factor between fog and edge computing is the location where data processing occurs:
- In edge computing, data is processed directly on the data sources such as sensors or IoT devices, or on the devices to which the sensors are connected.
- On the other hand, fog computing shifts computing tasks to an IoT gateway or fog nodes that are located in the LAN network.
Fog computing seems to be more appealing to data processing companies and service providers, while edge computing is popular with middle-ware and telecom companies that work with backbone and radio networks. Nonetheless, both fog and edge computing are designed to deal with one key problem—latency and response time.
How fog computing works
The fog computing network architecture is made up of a variety of components and functions, including fog nodes (IoT gateways) that accept data from IoT devices, as well as network devices such as routers and switches for connecting assets within a network. The fog nodes are located closer to the data source and have higher processing and storage capabilities. Fog nodes can process the data far quicker than sending the request to the cloud for centralized processing.
Any device with computing, storage, and network connectivity such as industrial controllers, switches, routers, and embedded servers can act as fog nodes. Fog nodes can be deployed in office buildings, factory floors, power poles, railway tracks, vehicles, oil rigs, and other target areas. When an IoT device generates data, the data is sent directly to a fog node for analysis instead of a cloud-based server. In an IoT environment for instance, the steps for transferring data through a fog network is as follows:
- Signals from IoT devices are sent to an automation controller which executes a control system program to automate those devices.
- A control system program sends data using an interoperability protocol for data exchange in IoT called Open Platform Communications (OPC) server—the OPC server is a software program that converts the hardware communication protocol into the OPC protocol.
- The OPC server converts the raw data into a protocol that can be more easily understood by web-based services such as HTTP(s) or MQTT (Message Queuing Telemetry Transport). The MQTT protocol is particularly designed for connections with remote locations where network bandwidth is limited.
- After conversion, the data is sent to a fog node or IoT gateway—which collects, processes, and saves the data or in some cases transfers it to the cloud for further analysis.
Now here’s what happens in the cloud platform when the data is successfully transferred:
- The cloud server collects and aggregates processed IoT data from the fog nodes.
- The cloud server performs further analysis on the IoT data and data from other sources to gain actionable business insights.
- Where necessary, the cloud server can send new application rules to the fog nodes based on those insights
When to consider fog computing for your business
The rapid growth in the use of IoT devices has resulted in an increased volume of digitally generated data. Managing that data has become a major challenge for most businesses operating in this sector. Industry experts have made it clear that the cloud-computing based IoT network models used by most businesses today are ill-equipped to deal with the massive amount of data that is and will be generated by the increasing number of IoT devices. The fog computing model is best suited to deal with those issues.
You know your business is ripe for fog computing if:
- You have IoT-based systems with geographically dispersed end devices generating data in the order of terabytes, and where connectivity to the cloud is irregular or not feasible.
- Massive amounts of data are constantly being collected from data sources such as connected cars, vehicles, ships, factory floors, roadways, farmlands, railways, etc., and transmitted to the cloud.
- You have to regularly analyze and respond to time-sensitive generated data in the order of seconds or milliseconds.
If you find yourself at this crossroad, this may be a good time to consider deploying fog computing in your network. Generally speaking, fog computing is best suited for organizations that need to analyze and react to real-time data in a twinkling of an eye. Fog computing’s ability to accelerate awareness and response to events with minimal latency makes it perfect for this task. For example, in the transportation sector where real-time data needs to be collected from vehicles at the edge of your network, fog computing provides an efficient way to aggregate data and generate real-time analytics and insights without depending on remote cloud servers.
There are a variety of use cases that have been identified as potential ideal scenarios for fog computing. Examples include wearable IoT devices for remote healthcare, smart buildings and cities, connected cars, traffic management, retail, real-time analytics, and a host of others. The OpenFog Consortium founded by Cisco Systems, Intel, Microsoft, and others is helping to fast track the standardization and promotion of fog computing in various capacities and fields. There’s already a rapid proliferation of fog applications in manufacturing, oil and gas, utilities, mining, and the transportation sector. Companies that adopt fog computing gain deeper and faster insights, leading to improved business agility and performance.
Four reasons why your business needs fog computing:
- Operate in remote locations: Operating in remote locations can be challenging, especially when internet connectivity is unreliable. Under the fog computing model, you easily can use local computing power to process and analyze generated data. Processed data can then be sent to the cloud for broader use when the internet connection is stable.
- Minimize latency: Today’s time-sensitive business applications demand a response time in the order of seconds or milliseconds, especially when timely corrective actions are required. The fog computing model is a better alternative to cloud computing when it comes to minimizing latency and enabling quick decision-making.
- Address security and privacy concerns: Under the cloud model, data is stored and processed on someone else’s computer. Sending sensitive IoT or operational data directly to the cloud puts the data and your edge devices at risk. The integrity and availability of the data and critical infrastructure may not always be guaranteed. Fog computing helps minimize this sort of risk, and enables faster responses.
- Conserve network bandwidth: It takes a lot of bandwidth to transfer large amounts of data from the edge of the network to a cloud server. Imagine a situation where each of your IoT devices generates 100GB of data per day, and you have thousands of them in the field. It could take days to transfer this vast amount of data from thousands of edge devices to the cloud. The cost of transferring this data on a daily basis could lead to unbearable bandwidth costs in the long run.
Benefits of fog computing
Fog computing provides a good number of benefits to businesses, some of which includes:
- Low latency: One of the key benefits of fog computing is the significant decrease in latency and response time. Because a lot of data is stored locally, the computing is performed faster, and the fog network can process large volumes of data with minimal delay. Furthermore, the processed data is most likely to be needed by the same devices that generated the data, so that by processing locally rather than remotely, the latency between input and response is minimized.
- Business agility: Fog computing offers companies, especially start-ups the flexibility they need in developing and deploying applications. With the right tools, developers can quickly develop and deploy fog applications where needed.
- Lower operating expense: By processing data locally instead of sending it to the cloud, you save on bandwidth cost which would have been unavoidable if you were sending the huge amount of IoT data directly to the cloud.
- Online and offline access: Fog computing requires data to be mostly stored within the LAN, and sent to the cloud only when necessary. This makes it ideal in scenarios where there is no internet bandwidth connection to send data. Systems running in remote or geographically challenging locations where access to the internet may be unreliable or unavailable greatly benefit from fog computing.
- Real-time analytics: Fog computing eliminates the inefficiency and latency that comes with cloud services through real-time analytics. Many organizations capitalize on the competitive advantage provided by real-time data analysis to stay ahead. For instance, companies in the manufacturing sector need to be able to react to events as they happen; financial institutions need real-time data to inform trading decisions or monitor for fraud. Fog computing deployments can help facilitate the speedy transfer of these real-time data.
Limitation of fog computing
Despite the fact that fog computing provides valuable benefits to organizations, it is not without some drawbacks. Here are some of the limitations you need to consider before you make the leap to fog computing:
- Security and privacy risks: Connected fog computing devices are rarely authenticated. This makes them vulnerable to various forms of cyberattacks such as DDoS and man-in-the-middle if adequate protections are not in place. Fog computing also raises concerns regarding end-user privacy. Fog nodes collect sensitive data from devices at the edge of the network. An intruder can easily gain access to this data with little or no resistance.
- Energy consumption: Fog nodes require a high amount of energy for them to function. The more fog nodes you have in your network, the greater the power consumption requirement. This can be a challenge for some organizations to manage. Most companies often try to minimize their energy requirement by using energy-efficient fog devices and nodes.
- Unsafe physical location: Due to the dispersed nature of fog nodes, chances are some of them will be located in less secure environments. Malicious actors can easily gain access to them, and this increases their risk of man-in-the-middle attacks.
- Network complexity: A fog computing network can be very complex to manage especially when combined with traditional infrastructure and cloud services. Managing these devices and nodes, including patch management can be a very difficult task. This could add more complexity to the network.
Conclusion
With over 30 billion IoT devices already connected, and 75 billion due to go online by 2025, the future of IoT systems certainly signals more connected things. The Fourth Industrial Revolution—a convergence of technologies such as 5G networks, artificial intelligence, quantum computing, cloud, and fog computing promises to bring new benefits with IoT-based systems.
The cloud computing model is not suitable for IoT applications that process large volumes of data in the order of terabytes and require quick response times. This is where the fog computing model stands out. Organizations with time-sensitive IoT-based applications with geographically dispersed end devices, where connectivity to the cloud is irregular stand to benefit from this technology.
Fog computing FAQs
What is offloading in fog computing?
Offloading occurs when volumes of data cannot be processed remotely in a timely and efficient manner. In these circumstances, the processing of endpoint data is moved to a local node, which preprocesses and filters data, serving some requests autonomously and referring to a cloud server. This is a little like a proxy server, which operates on the local network.
What is distributed fog computing?
Fog computing can be considered a distributed architecture because data processing is performed locally, so a central server that serves many networks will push its activities through to many local servers.
