
Graylog is a robust, open-source log management platform designed to help organizations efficiently gather, index, and analyze log data across their IT environments. By consolidating logs from multiple sources, it streamlines monitoring, troubleshooting, and security oversight, making it easier to manage complex systems.
One of Graylog’s key strengths is its ability to provide real-time log analysis and search. IT teams can quickly identify issues and take corrective action before problems escalate. Its scalable architecture allows the platform to handle large volumes of data, making it suitable for organizations of any size.
Centralization is another major advantage. Graylog can aggregate logs from servers, applications, network devices, and security tools, giving users a unified view of system performance and network health. Its intuitive interface enables filtering, searching, and visualizing log data, which greatly improves efficiency in troubleshooting and optimizing systems.
Beyond collection and analysis, Graylog offers advanced features such as customizable alerts, interactive dashboards, and detailed reporting. These tools help teams respond to incidents in real time and track operational trends over time. Integration with other platforms, such as Elasticsearch, enhances its search and analytics capabilities, providing even deeper insights into system activity.
Graylog shares similarities with tools like Elasticsearch and Splunk. While all three started as free solutions, they have evolved into more comprehensive platforms with multiple modules and paid options. Graylog itself now offers a hosted version, reflecting its shift toward a commercial model.
This guide explores Graylog’s core features, different editions, and comparable tools, helping users understand how to leverage the platform for effective log management and system monitoring.
What exactly can Graylog do?
Graylog is a flexible log management system that was designed to create clarity from massive amounts of logs and other data sources. If you’re a sysadmin or have been in the IT space for some time, you’ll know just how challenging it can be to find the right information from an ugly unformatted log file.
As log files and other data enter Graylog they can be sorted and visualized. As you can imagine having this level of clarity across your multiple platforms could be incredibly insightful. Industries such as MSPs, Telecom, DevOps, and FinTech can all benefit greatly from bringing data together in one cohesive manner.
As companies grow it seems like there is more and more data in increasingly more places; centralizing and making sense of it all is what Graylog was designed to do.
How does Graylog work?
For every server or log file you want to pull into Graylog, a client agent will need to be installed. Thankfully, this is a very straightforward process and has the potential to be automated via GPO or any other form of scripting. Once the agent is installed, it begins pulling log information directly back into the Graylog main server.
Once the data arrives it can be automatically visualized, stored, or broken down and analyzed manually through a number of advanced search features. We’ll touch more on the power of these advanced searches further into the review.
How does Graylog store data?
By default, Graylog stores all data in Elasticsearch, which is an open-source search engine used by researchers and analysts across the globe. Having your data accessible with Elasticsearch gives you massive flexibility over a private third-party search tool. This gives you the power to not only create your own custom search queries but leverage the free scripts and tools that the Elasticsearch project has built over the years.
Closed search tools often act as black boxes with how your data is sorted. This not only restricts what you can do with your data but makes you dependent on your vendor for search solutions. With Elasticsearch, this is all transparent and customizable. Many core functions rely on Elasticsearch to work, so unfortunately there is no easy alternative to using Elasticsearch as a data search tool at this time.
Graylog Versions
Graylog currently has two main products, Graylog Open Source, and Graylog Enterprise. Let’s take a look at each product individually and see how its features compare.
Graylog Open Source
Graylog Open Source is a 100% forever-free version of Graylog that provides limited, but powerful log management functionality. For smaller DevOp teams or growing IT companies, the open-source edition of Graylog is a great way to get your data organized and in one place without ever opening up your wallet.
While most freemium software has huge holes where features should be, Graylog seems to almost take the opposite approach. At the free level you’ll be able to process up to 5GBs of data per day, and still access many of the features that actually matter, such as alerts, API access, and LDAP integration. One of the best parts of open source Graylog is that your data isn’t locked into a platform. Some free log management tools make it easy to get data in, but then difficult to migrate out.
The open-source edition lets you get a fair feel for the platform without locking you into it. If you’re using Graylog to simply collect your logs from other places, you can configure Graylog to only copy the data from those sources. This means you can always go back to the way your data was organized before you tested out Graylog.
While I’d usually warn businesses to steer clear of open-source products due to their lack of support, Graylog makes the transition into their Enterprise version virtually seamless. So if you’re not at the point where you think you’d need features like data forwarding or scheduled reports, that’s something you can easily grow into with Graylog. You can check out a direct comparison between the two versions.
Graylog Enterprise
While the open-source version of Graylog provides a great start to log management, it’s only the tip of the proverbial iceberg. Businesses who are looking to leverage the full power of their logging data will find that Graylog provides almost anything you could ask for in a log management solution. Below we’ll break down and review some of the key features that Graylog brings to the table.
Search Workflows
Graylog utilizes a feature called Search Workflows to help save time on repetitive search queries. It’s common for data analysts and researchers to run similar search queries to help identify issues or produce reports; this feature was built to speed that process up.
When you create a workflow you’re combining multiple search queries into a template that can be executed with a single action. When the workflow completes, the output can automatically be displayed through a chart or other graphic on the monitoring dashboard.
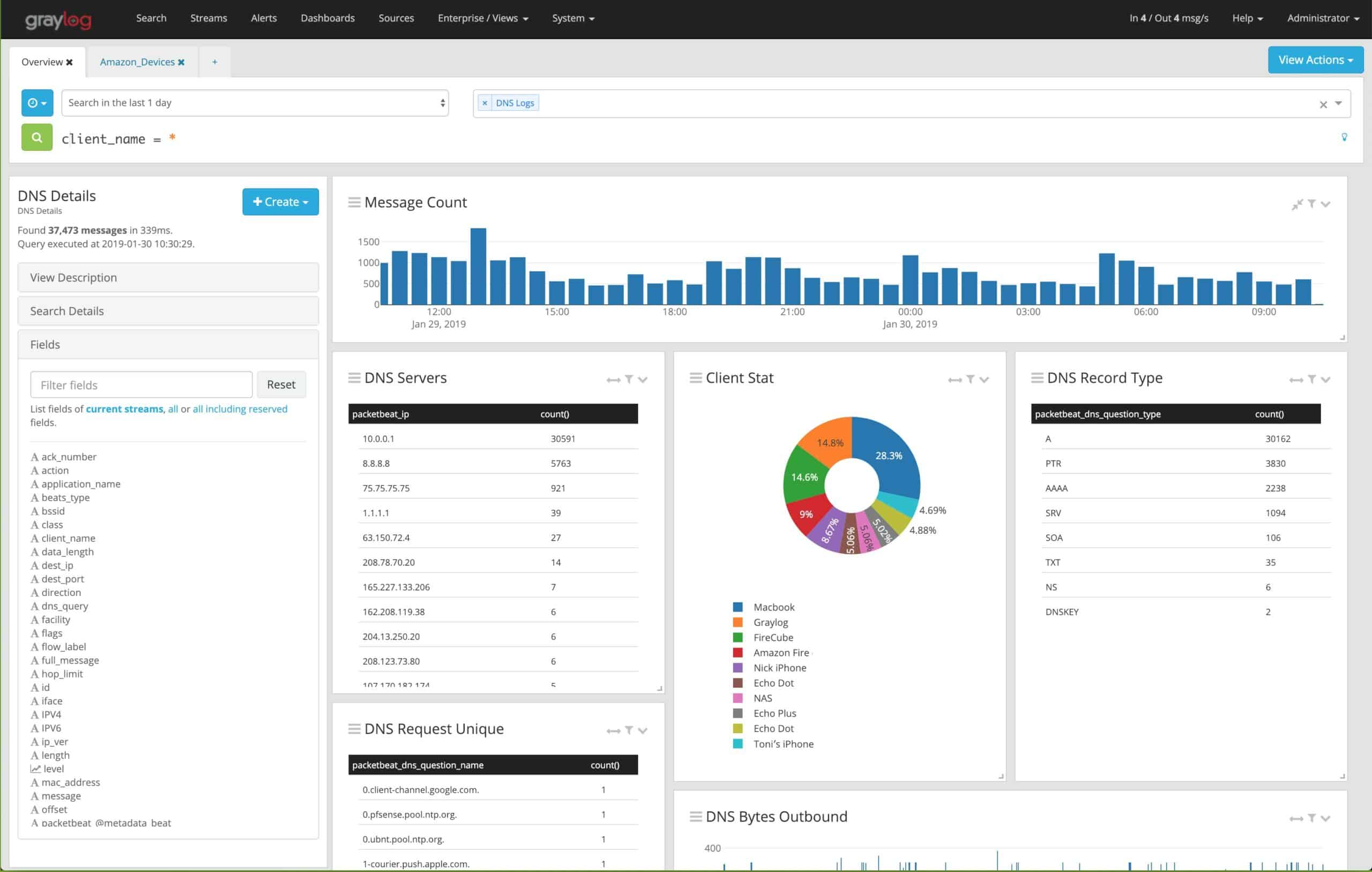
When you create a workflow you’ll also have the option to save it for later, and even share it with your team. Over time you can build a library or search workflows to make resolving complex problems a whole lot easier.
You can use any number of parameters to build a search workflow which means there’s no limit to how specific you can get. A feature I personally enjoyed was the ability to move data from one workflow directly into another. If your goal or investigation ever changes you can select the relevant data and port it over as a parameter into an entirely different workflow for processing.
Alerts & Triggers
Alerts can be accessed via the alerts tab at the top of Graylog for quick access. Each alert is color-coded to indicate if its status is resolved, or unresolved, which is a nice feature for quickly going over alerts at a glance. Clicking on each alert gives you additional details such as the condition that was met, and what data stream it originated from.
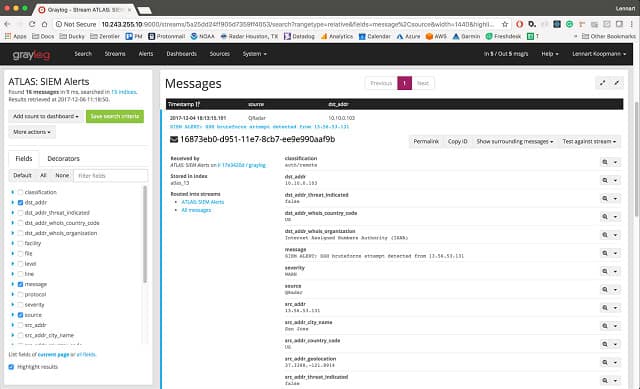
In the same menu, you can view your conditions that are in place to trigger an alert. Conditions can be created from scratch, or downloaded from knowledge packs that are ready to implement right away. Creating a new condition is pretty straightforward, simply pick a data stream where those logs would be flowing from and then pick a condition type. These condition types could range from detecting specific values like a domain or workstation number, or alert based on a number value threshold being broken.
Alerting works in a similar fashion. You pick a data stream that you want to get alerted on and then choose from email, HTTP, or custom script to get notified. The HTTP alert allows you to integrate with apps such as Slack, while the custom script notification can execute a script to either alert you, or deploy automated remediation. To avoid alarm fatigue, you can easily set thresholds to each of your events, and aggregate that data into groups to keep your dashboard clear.
Content Packs
The content packs are truly a game-changer in the world of log management. While most logging software gives you either very limited templates or nothing at all, Content packs provide a truly out-of-box experience for data management.
The time it takes to start receiving value from log management has always been a problem, and content packs were created specifically to fix that. These packs consist of pre-built inputs, intelligence processing, display templates, and even alerts and reports that are ready to go. All of these settings can be changed or configured which takes much less time than building everything from the ground up.
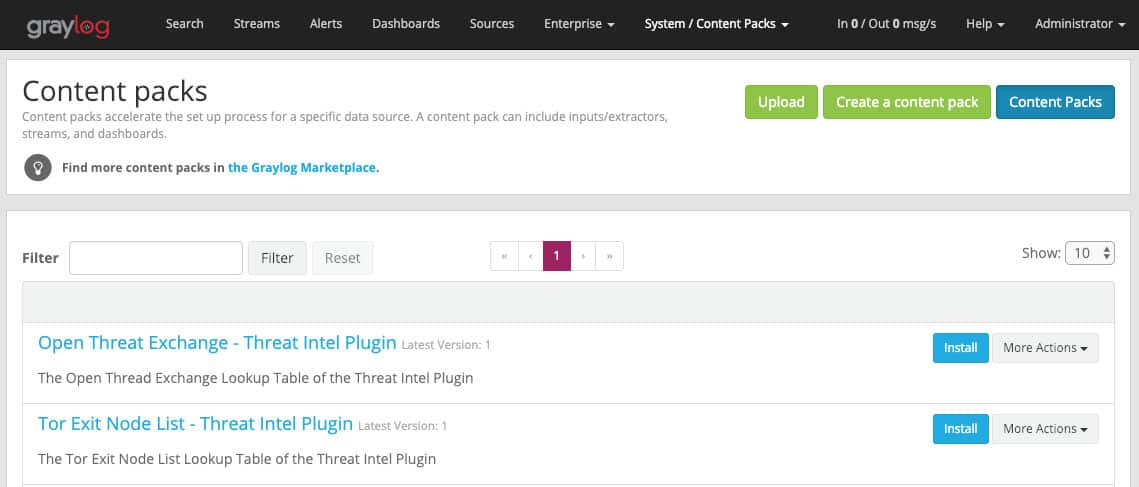
Content packs can be found through the Graylog marketplace where a community of Graylog members shares their packs, usually for free. A readme file provides all of the pack’s details so you’ll be confident you know exactly what you’re getting. Pack installation is as easy as browsing to the file you’ve downloaded and selecting Install. You’ll get a chance to parse over the entire configuration of the content pack one final time before installing.
If you want to share a content pack or save one for your organization, that can be done through a simple wizard under the content pack section.
Correlation Engine
The correlation engine is the real ‘meat and potatoes’ of Graylog and is the mechanism that automatically extracts key information from raw log data. You can create strings of conditions that trigger specific alerts or fire off scripts for corrective action.
Using the correlation engine did take some time, and does have a bit of a learning curve if you’ve never created advanced filters or rulesets before. Luckily, there’s plenty of documentation that comes in handy while experimenting with this feature.
Some common use cases for the correlation engine range from intrusion detection, to viewing patterns in authentication failures. This feature can be as simple, or as complex as you need it to be depending on your needs and creativity.
Graylog Sidecar
Graylog Sidecar allows you to centralize your configuration templates for each of your Graylog agents to help improve consistency and the speed at which you deploy new agents. The system works by allowing you to create and tag configurations from a single Sidecar dashboard. For instance, you can tag all of your Apache logs with ‘Apache’, to ensure that all of your Apache logs are getting filtered and sorted the same way across all of your servers.
If you run a larger environment or work in a managed service environment Graylog Sidecar will be considerably more valuable to you. You’ll have the option to create templates around each type of server or data stream you wish to collect and ensure that it’s consistent across all environments.
If you need to be even more granular you can create specific templates and assign them to groups of devices. This could be used to pull specific data from different departments or physical locations in a network. Sidecar supports some of the most common agents such as Filebeat, Winlogbeat, and NXlog. Sidecar works off of a modular architecture so other agent types could be supported as well.
Related post: Graylog Vs Splunk
Alternatives to Graylog
While Graylog is certainly an excellent choice for log management and security intelligence, you may want to look into how it compares with similar tools. If you’re looking for an in-depth breakdown of the best security and event-logging tools, be sure to check out our list of the Best SIEM Tools.
Below is a list of some of the most popular alternatives to Graylog:
- Site24x7 Log Management (FREE TRIAL) This service is part of a cloud platform of many system monitoring and management tools. It collects, consolidates, and files most log message formats, including Syslog messages and Windows Events.
- Datadog Shares similarities with Graylogs Log Analysis and monitoring features. Datadog was also built for the IT industry and provides out of the box solutions for log management and network monitoring.
- Splunk Utilizes log data and other information to create reports and provide users with operational intelligence powered by data in real-time.
- Dynatrace Provides users with a holistic monitoring solution that leverages automation and log collection to build actionable reports and business analytics.
- SolarWinds Server & Application Monitor SolarWinds’ SAM was built to monitor a wide variety of servers and apps through a simple agent install. SAM condenses alerts, monitors, and network data into a single manageable dashboard.
- OSSIM An open-source tool that uses a combination of real-time and historic log data to help increase security across the network.
- Logz.io This open-source cloud-based platform allows you to monitor and troubleshoot your on-premises or cloud services through insights populated by ELK powered log management tools.
Graylog FAQs
What is the use of Graylog?
Graylog is a manager for unstructured data. However, as its name suggests, the main usage of Graylog is to manage log messages. The tool is a log server that will receive and organize log messages from many sources, putting them into a common format. The log messages can then be filed with indexing for fast retrieval. Messages can be read into a data viewer live or loaded into the system from files. Messages in the data viewer can be sorted, filtered, grouped, and summarized for analysis. It is also possible to set up detection scripts that scan through arriving messages for tasks such as security monitoring.
What language does Graylog use?
Graylog is written in Java and the software runs on Linux.
Is Graylog free to use?
There is a version of Graylog that is free to use. This is called Graylog Open and it provides a log server, log manager, and an analysis package. You can write your own applications in Graylog to search through live data as it arrives for performance monitoring or security scanning. Graylog Operations is a paid version of Graylog but you can use it for free to process 2 GB of data per day.
