

TCP/IP, short for Transmission Control Protocol/Internet Protocol, is a foundational suite of standards that governs how devices communicate across networks. It establishes the framework that allows data to move reliably from one location to another. Although the suite includes many protocols, its name highlights the two most essential components: TCP and IP. A key concept within this system is addressing, which determines how devices identify and interact with each other across a network.
The creation of TCP/IP was driven by the need for a universal set of rules that would allow devices and software from different manufacturers to communicate seamlessly. Before its introduction, networking was largely controlled by proprietary systems, where major corporations dictated how devices connected. These closed ecosystems forced customers to rely on a single vendor for all networking equipment, leading to inefficiencies and limiting innovation.
TCP/IP transformed this environment by introducing open, standardized protocols that anyone could adopt. This shared “rulebook” removed many of the barriers imposed by vendor-specific technologies, making it easier for developers to build interoperable software. Businesses also gained the flexibility to combine hardware and systems from different providers without worrying about compatibility.
Today, TCP/IP underpins the internet and most modern networking environments, enabling systems and devices worldwide to connect and exchange data efficiently. Its open and scalable design continues to drive innovation, ensuring reliable communication across increasingly complex networks.
If you don’t have time to read the whole post and just want a summary of the tools we recommend, here’s our list of the best TCP/IP tools:
- Men & Mice IP Address Management EDITOR’S CHOICE Free IPv4 to IPv6 transition tool or a full, paid IPAM.
- IPv6 Tunnel Broker Free online IPv6 tunneling proxy.
- Cloudflare IPv6 Translation Address translation on an edge server offered as part of Cloudflare system protection services.
- SolarWinds IP Address Manager A dual-stack IPAM that coordinates with DHCP and DNS servers. Runs on Windows Server.
- SubnetOnline IPv4 to IPv6 Converter A subnet address calculator that can give you conversions from IPv4 to IPv6 addresses.
Networking concepts
Anyone can write a program to send and receive data over a network. However, if that data is being sent to a remote destination and the corresponding computers is not under the control of the same organization, software compatibility problems arise.
For example, a company may decide to create its own data transfer program and write rules that say the opening of a session begins with a message “XYZ,” which should be replied to with an “ABC” message. However, the resulting program will only be able to connect to other systems running the same program. If another software house in the world decides to write a data transfer program, there is no guarantee that its system will use the same messaging rules. If another company creates a communications program that starts a connection with a “PPF” message and expects an “RRK” response, those two networking systems would be incapable of communicating with each other.
This is a very close description of the networking world before TCP/IP existed. What made matters worse was that the companies that produced networking software kept their rules and messaging conventions secret. The operating methods of each networking system were completely incompatible. Such a strategy made commercial sense when all network software providers were competing in a limited geographical market. However, those corporate efforts to dominate the market prevented networking technology from spreading around the world because no networking company was big enough to reach every country in the world and establish itself as the universal standard. This lack of availability caused companies in other parts of the world to create their own standards, and the incompatibility of network software just got worse.
Non-proprietary standards
The Internet Protocol was created by academics who had no commercial motivations. They wanted to map out a common format that anyone could use. This reduced the power of those few companies that dominated networking technology, principally IBM and Xerox.
Those companies resisted the drive towards common standards in order to protect their monopolies. Eventually, the commercial advantages to a common standard became clear and the opposition to TCP/IP faded. Neutral, universal standards enabled companies to focus on one aspect of networking, such as the manufacture of routers or the creation of network monitoring software.
Trying to create a comprehensive communications system that covered all aspects of networking required so much development and coordination between departments that the creation of a new product was a very lengthy and expensive task. Universal standards meant that networking companies could release each element of a networking suite individually and compete to get that product integrated into a multi-vendor environment. This development strategy involved much less risk.
TCP/IP history
TCP/IP began life as the “Transmission Control Program.” Many people claim to have invented the internet but many consider Vint Cerf and Bob Khan the true creators. Cerf and Khan published “A Program for Packet Network Intercommunication” in May 1974. This paper was sponsored by the US Department of Defense and was published by the Institute of Electrical and Electronic Engineers.
ARPANet
From the outset, the central concept of TCP/IP was to make the standard publicly available even though its funding indicates that it was initially seen as a military tool. In fact, Vint Cerf, a professor at Stanford University in 1974, joined Bob Khan at the Defense Advanced Research Projects Agency where they further developed the internet concept. DARPA was instrumental in the creation of the internet and already had a forerunner of the system called ARPANet. Both Cerf and Khan worked on ARPANet projects while studying at university. ARPANet system development helped provide many of the technologies and procedures that Cerf and Khan eventually consolidated into TCP/IP.
Jon Postel
The main development that occurred to the Transmission Control Program is that it was split out into several different protocols. Another founder of internet technology, Jon Postel, got involved during the development stage and imposed the concept of a protocol stack. The layering system of TCP/IP protocols is one of its strengths and is an early, conceptual example of software services.
TCP/IP protocol stack
When writing a specification for an application that will operate across a network, many different considerations need to be laid out. The idea of a protocol is that it defines a common set of rules. Many functions of exchanging data across a network are common to all applications such as FTP, which transfers files. However, the procedures that set up a connection are the same as those for Telnet. So there isn’t any point in writing into the FTP standards all of the message structures needed to set up a connection. Common functions are defined in separate protocols and the new systems that rely on the services of those protocols don’t need to repeat the definition of supporting functions. This concept of supporting protocols led to the creation of the protocol stack concept.
Lower layers in the stack provide services to higher layers. The functions of lower layers have to be task specific and present universal procedures that can be accessed by higher layers. This organization of tasks reduces the need to repeat the definitions of tasks explained in lower-layer protocols.
Protocol model
The Internet Protocol Suite, the official name for TCP/IP stack, consists of four layers.
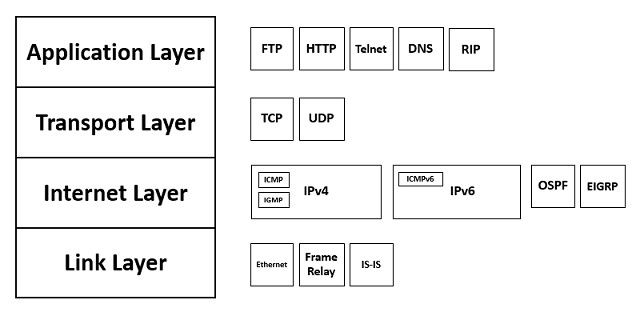
The Link Layer at the bottom of the stack prepares data to be applied to the network. Above that is the Internet Layer, which is concerned with addressing and routing packets so that they can cross interconnecting networks to arrive at a remote location on a remote network.
The Transport Layer is responsible for managing the data transfer. These tasks include encryption and segmenting a large file into chunks. The receiving transport layer program has to reassemble the original file. The Application Layer doesn’t just include apps that the computer user can access. Some applications are also services to other applications. These applications do not need to be concerned with how data is transferred, just that it is sent and received.
Protocol abstraction
The layering concept introduces levels of abstraction. This means that the task of sending a file is a different process to FTP than it is to TCP, IP, and PPP. Whereas FTP will send a file, TCP will establish a session with the receiving computer, break up the file into chunks, package each segment, and address it to a port. IP takes each TCP segment and adds on addressing and routing information in a header. PPP will address each packet and send it to the connected network device. Higher layers can reduce the details of services provided by lower layers down to a single function name, creating abstraction.
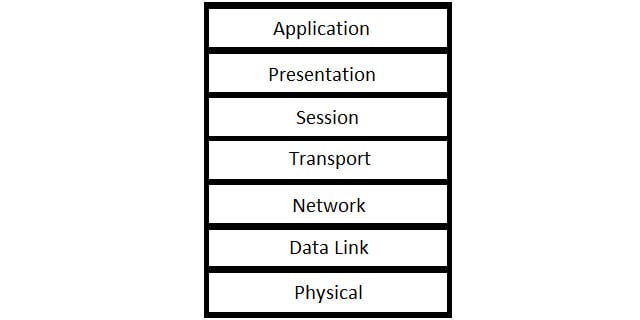
OSI concepts
The Open Systems Interconnection model is an alternative protocol stack for networking. OSI is newer than TCP/IP. This stack contains a lot more layers and so more precisely defines the tasks performed by many TCP/IP layer protocols. For example, the lowest layer of the OSI stack is the Physical Layer. This deals with the hardware aspects of a network and also how a transmission is actually going to be performed. These factors include the wiring of connectors and the voltage that represents a zero and a one. The Physical Layer does not exist in the TCP/IP stack and so those definitions have to be included in the requirements for a Link Layer protocol.
The higher layers of OSI divide TCP/IP layers into two. The Link Layer of TCP/IP is split into the Data Link and Network Layers of OSI. The Transport Layer of TCP/IP is represented by the Transport and Session Layers of OSI, and TCP/IP’s Application Layer is divided into the Presentation and Application Layers in OSI.
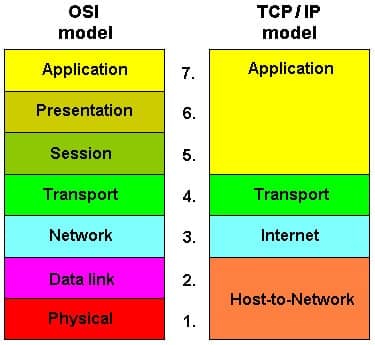
Although the OSI model is much more precise, and ultimately, more helpful than the Internet Protocol Suite, the prevalent protocols for the internet, IP, TCP, and UDP, are all defined in terms of the TCP/IP stack. OSI is not as popular as a conceptual model. However, the existence of these two models does create some confusion over what number layer a protocol or function operates at.
Generally, when a developer or engineer talks about layers in numbers, he is referring to the OSI stack. An example of this confusion is the Layer 2 Tunneling Protocol. This exists at the TCP/IP Link Layer. The Link Layer is the bottom layer in the stack, and so, if it is going to be given a number, it should be Layer 1. So, L2TP is a layer 1 protocol in TCP/IP terms. In OSI, the Data Link Layer lies above the Physical Layer. L2TP is a layer 2 protocol in OSI terminology, and that’s where it gets its name.
TCP/IP documentation
Although that first definition of TCP/IP was published by the IEEE, the responsibility for managing most networking protocols has moved over to the Internet Engineering Taskforce. The IETF was created by John Postel in 1986 and it was originally funded by the US government. Since 1993, it has been a division of the Internet Society, which is an international non-profit association.
Requests for Comments
The publishing medium for networking protocols is called an “RFC.” This stands for “request for comments” and the name implies that an RFC describes a protocol that is under development. However, the RFCs in the IETF database are final. If the creators of a protocol wish to adapt it, they have to write it up as a new RFC.
Given that revisions become new documents and not amendments to original RFCs, each protocol can have many RFCs. In some cases, a new RFC is a complete rewrite for a protocol, and in others, they only describe changes or extensions, so you have to read earlier RFCs on that protocol in order to get the full picture.
RFCs can be accessed for free. They are not copyrighted, so you can download them and use them for your development project without having to pay a fee to the protocol’s author. Here is a list of the key RFCs that relate to the TCP/IP stack.
Internet Architecture
TCP/IP evolution
Internet Protocol
TCP
UDP
Link Layer protocols
The Transmission Control Program was split into two protocols placed at different layers on the stack. Those were the Transmission Control Protocol at the Transport Layer and the Internet Protocol at the Internet Layer. The Internet Layer gets data packets from your computer to another device on the other side of the world. But a lot of work is needed just to get from your computer to your router, and that isn’t the concern of internet protocols. So, the designers of TCP/IP slid in another layer below the Internet Layer.
This is the Link Layer and it is concerned with communications within a network. In TCP/IP, anything that involves getting a packet from a computer to an endpoint on the same network is categorized as a Link Layer task.
Many network specialists have a protocol they regard as the key standard at the Link Layer. This is because the wide spectrum of tasks that TCP/IP assigns to the Link Layer underpins many different job titles, such as network cabling engineer, network administrator, and software developer. Arguably, the most important system pigeonholed into the “Link Layer” is Media Access Control (MAC).
Media Access Control
MAC has nothing to do with Apple Macs. The similarity in the name between the standard and the computer model is a complete coincidence. The tasks involved in getting your data onto a wire are all the responsibility of MAC. In OSI terminology, MAC is an upper subsection of the Data Link Layer. The lower section of that layer is fulfilled by Logical Link Control functions.
Although the Internet Engineering Taskforce was set up to manage all networking standards, the IEEE wasn’t willing to relinquish control of lower layer standards. So, when we get down to the Link Layer, many of the protocol definitions are part of the IEEE’s library.
In the division of labor between Link Layer protocols, the MAC element takes care of the software that manages transmissions within networks. As such, tasks like local addressing, error detection, and congestion avoidance are all MAC responsibilities.
As a network administrator, you will come into contact with the abbreviation “MAC” many times a day. The most visible part of the MAC standard is the MAC address. This is actually the sequence number of a network card. No device can connect to a network without a network card, and so every network-enabled piece of equipment in the world has a MAC address. The IEEE controls the allocation of MAC addresses and ensures that each is unique throughout the world. When you plug a network cable into your computer, at that point, the only identifier it has is its MAC address.
At the Link Layer, the MAC address is more important than the IP address. Systems that automatically allocate IP addresses to devices operate their initial communications using the MAC address. The MAC address is printed on every network card and is embedded into its firmware.
Protocols and equipment
You probably have a range of network equipment in your office. You will have a router, but you probably also have a switch, and maybe a bridge and/or a repeater as well. What is the difference between these?
The difference between a router, a switch, a bridge, and a repeater can best be illuminated by referring to that device’s position in relation to the TCP/IP and OSI stacks.
Router
A router sends your data out over the internet. It also deals with endpoints on your local network, but only when they communicate beyond that router’s domain. The router is the home of the Internet Layer. In OSI terms, it is a Layer 3 device.
Switch
A switch connects together all of the computers on your network. Each computer only needs one cable leading out of it and that cable leads to a switch. Many other computers in the office will also have a cable going into the same switch. So, a message gets from your computer to another computer in the office through the switch. A switch operates at the Link Layer. In the OSI stack, it is at the Media Access Control sub-level of the Data Link Layer. That makes it a Layer 2 device.
Bridge
A bridge connects one hub to another. You could use a bridge to connect a LAN and a wireless network together. A bridge is a switch with just one connection. Sometimes switches are called multi-port bridges. Bridges don’t need very complicated processors. They are just a pass-through, so they are principally Physical Layer devices. However, because they engage in addressing, they do also have some Link Layer capabilities. This makes them (OSI) Layer 1/Layer 2 devices.
Repeater
A repeater extends the range of a signal. On cables, the electric pulse dissipates over distance, and in wifi, the signal gets weaker as it travels. A repeater is also known as a booster. On cables, it applies a new boost of electricity to transmissions and on wireless networks, it retransmits signals. A repeater needs almost no software. It is a purely physical device, so it doesn’t really have any involvement with the protocols in the TCP/IP stack. In OSI, it is a Physical Layer device, which makes it Layer 1.
TCP/IP addressing
The main feature of the Internet Protocol is its standard for addressing devices on networks. As with the postal system, no two endpoints can have the same address. If two computers connect with the same address, the routers of the world wouldn’t know which one was the intended recipient of a transmission to that address.
Addresses only need to be unique within an address space. This is a great advantage for private networks because they can create their own address pool and distribute addresses regardless of whether or not those addresses are already in use on other networks in the world.
Another concept to keep in mind when dealing with addresses is that they only need to be unique at one moment in time. This means that one person can use an address to communicate over the internet, and when they go offline, someone else can use that address. The fact that addresses on private networks don’t have to be unique throughout the world and the concept of uniqueness in the moment helped to ease the rate at which IP addresses were allocated. This is a good thing, because the pool of available IPv4 addresses in the world has run dry.
IPv4
By the time the Internet Protocol was in a workable state, it had been adjusted and rewritten up to its fourth version. This is IPv4 and its address structure is still in operation today. It is likely that the IP addresses in use on your network all follow the IPv4 format.
An IPv4 address is made up of four elements. Each element is an octet, which means it is an 8-bit binary number. Each octet is separated by a dot (“.”). For ease of use, those octets are usually represented by decimal numbers. The highest decimal number that can be reached by an octet is 255. This is 11111111 in binary. So, the highest IP address possible is 255.255.255.255, which is really 11111111.11111111.11111111.11111111 in the underlying binary. This sequencing method makes a total number of 4,294,967,296 addresses available. About 288 million of those available unique addresses are reserved.
The distribution of available IP Addresses is controlled by the Internet Assigned Numbers Authority. The IANA was set up in 1988 by Jon Postel. Since 1998, IANA has been a division of the Internet Corporation of Assigned Names and Numbers (ICANN), which is an international non-profit organization. IANA periodically distributes ranges of addresses to each of its divisions, known as Regional Internet Registries. Each of the five RIRs covers a large area of the globe.
Private network addressing
Within a private network, you don’t have to apply to IANA or its divisions to get IP addresses. Addresses only have to be unique within a network. By convention, private networks employ addresses within the following ranges:
- 10.0.0.0 to 10.255.255.255 — 16 777 216 available addresses
- 172.16.0.0 to 172.31.255.255 — 1 048 576 available addresses
- 192.168.0.0 to 192.168.255.255 — 65 536 available addresses
Big networks can get congested thanks to the large number of devices trying to access the physical cable. For this reason, it is common to divide networks up into sub-sections. These subnetworks each need exclusive address pools allocated to them.
This address scope division is called subnetting and you can read more about this addressing technique in The Ultimate Guide to Subnetting.
IPv6
When the creators of the Internet Protocol were working on their idea back in the 1970s, the plan was to make a network that could be accessed by anyone in the world. However, Khan, Cerf, and Postel could never have imagined how extensive that access would become. That pool of more than 4 billion addresses seemed big enough to last forever. They were wrong.
By the early 1990s, it became clear that the IP address pool was not large enough to meet demand forever. In 1995, the IETF commissioned a study into a new address protocol that would provide enough addresses. This project was called IPv6.
What happened to IPv5?
There never was an Internet Protocol version 5. However, there was an Internet Stream Protocol, which was written in 1979. This was a forerunner of VoIP and it was intended to have a parallel packet header. The difference between the IPv4 header and the streaming header was indicated by the version number in the IP header. However, the Internet Stream Protocol was abandoned and so you will never encounter an IPv5 packet header.
IPv6 address format
The simplest solution to IP address exhaustion was to just add more octets to the standard IP address. This is the strategy that won out. The IPv6 address includes 16 octets, instead of four in the IPv4 address. This gives the address a total of 128 bits and makes a pool of more than 340 undecillion addresses. An undecillion is a billion billion billion billion and is written as a one with 36 zeros after it.
The final layout of the IPv6 address was published in February 2016 as RFC 4291. The definition has since been revised and extended by later RFCs.
A clever feature of IPv6 addresses is that trailing zeros can be omitted. This makes backwards compatibility a lot simpler. If your current IP address is 192.168.1.100, you also have the IPv6 address 192.168.1.100.0.0.0.0.0.0.0.0.0.0.0.0.
A complication lies in the notation for IPv6, which is not the same as that for IPv4. The IPv6 address is broken up into 2-octet sections. Each section is written in hexadecimal and so contains four digits. Each character in the address represents a nibble, which is 4 bits, of the underlying binary number. The final difference is that the separator changed from a dot (“.”) to a colon (“:”). So to make an IPv4 address into an IPv6 address, first convert the decimal numbers of your address into hexadecimal.
192.168.1.100
= C0.A8.01.64
Next, join together segments 1 and 2 and segments 3 and 4. Separate them with colons.
= C0A8:0164
Add on six zero segments to make up the size of an IPv6 address.
= C0A8:0164:0000:0000:0000:0000:0000:0000
The changes in notation shouldn’t make any difference to the processing of IP addresses because in computers and networking hardware, addresses are viewed as a long string of binary. The dot and colon notation and the conversion into decimal or hexadecimal is just for display purposes.
IPv6 implementation
IPv6 is live now. In fact, IPv6 addresses have been available since 2006. The last IPv4 addresses were distributed to RIRs by IANA in February 2011 and the first regional authority to exhaust its allocation was the Asia-Pacific Information Center. That happened in April 2011. Rather than switching over from one system to the other, the two addressing systems are running in parallel. As explained above, an IPv4 address can be handled by IPv6-compatible equipment, simply by padding it out with zeros.
The problem is that not all equipment on the internet is IPv6-compatible. Many home routers can’t handle IPv6 addresses and most ISPs haven’t bothered to implement the system. Services that implement dual-stack services to cater to both address systems are usually slower than those services that ignore IPv6 completely.
Although experts stand overwhelmingly in favor of transitioning to IPv6, commercial networks seem remarkably reluctant to move. This may be because it requires time, and time has a cost. Businesses seem unwilling to allocate a budget to transition to IPv6 until it is a vital business priority. Network administrators seem to get no rewards from executives for planning ahead.
So, if you are a network administrator with a tight-fisted CFO, you need to play smart with network administration tools. You can squeeze through your IPv6 transition by using free tools, or make sure your next big network administration software purchase includes a facility for IP address transition. More on that later.
Transport layer protocols
The Internet Protocol is the star of TCP/IP because it gave its name to the internet, which is beloved by all. The Transport Layer was created to house the co-star of TCP/IP, the Transmission Control Protocol. Remember TCP/IP was originally called the Transmission Control Program. So, transmission control was at the front of Cerf and Khan’s minds when they devised this protocol suite.
The original idea in the TCP/IP plan was that software designers could have a choice. They could either establish a connection with TCP or bypass connection procedures and send out packets directly with IP. Postel’s insistence on enforcing stack layers meant there needed to be a packaging process to prepare streams for direct transfers. This led to the creation of the User Datagram Protocol (UDP). UDP is the main alternative to TCP. The lack of interest in this protocol is illustrated by the short list of RFCs it generated. The original definition of UDP is still current and it has never been updated.
So, let’s take a closer look at these two pillars of the TCP/IP Transport Layer.
Transmission Control Protocol
TCP sets up a connection. You might think that any transmission involves a connection, but the true meaning of the term engenders creating a session and maintaining it. That task requires administrative messages. So, TCP creates a bit of overhead on every network transaction.
The good news is that the procedures of TCP are no different for connections to remote computers over the internet than they are for connections between devices on the same LAN. The three phases of a TCP session are establishment, management, and termination.
TCP has some weaknesses that hackers and attackers can exploit. A typical distributed denial-of-service (DDoS) attack uses the session establishment procedures of TCP, but leaves the process unfinished. In a TCP session creation process, the initiating device sends a SYN packet. The receiving computer replies with a SYN-ACK, and the initiate finishes the set up with an ACK message. A DDoS attack sends a SYN but doesn’t reply to the SYN-ACK with an ACK. That leaves the recipient hanging for a while, waiting. The receiver will time out, but that few seconds of delay ties up the server and makes a flood of SYN messages very effective at blocking out genuine traffic.
The TCP service is responsible for splitting up a stream or a file into segments. It puts a frame around each segment, giving it a header. The TCP header doesn’t include the IP address or a MAC address, but it does have another level of address: the port number. The header includes an origin and destination port number. The port number is an identifier for the application on either side of the connection involved in exchanging data.
The header also includes a sequence number. This applies to segments of the same stream. The receiving TCP program reassembles the stream by referring to the sequence number. If a segment arrives out of sequence, the receiver holds it and waits for the missing part before completing the stream. This process involves buffering and can cause delays on transmitted data arriving in the application that requested it. Another header field is a checksum. This enables the receiver to detect whether the segment arrived intact.
The two TCP programs involved in the connection create an orderly termination when the transmission finishes, known as “graceful degradation“.
User Datagram Protocol
Whereas the functionality of TCP has been included in TCP/IP from the system’s inception in 1974, the definition of UDP appeared much later in 1980. UDP is provided as an alternative to TCP. The original intention was to have a logical route through TCP to create a connection and an alternative path that just went straight to IP procedures, cutting out the connection processes. However, that strategy would have required the inclusion of conditional branches in the definition of the Internet Protocol, which made the requirements of that protocol unnecessarily complicated. UDP was provided to emulate the segment creation features of TCP without including any connection procedures.
Whereas the TCP data unit is called a segment, the UDP version is called a datagram. UDP just sends out a message and doesn’t check whether that message arrived or not. The receiving implementation of UDP strips off the datagram header and passes it to the application.
The UDP header is much smaller than the TCP header. It contains just four fields, each of which is two bytes wide. The four fields are source port number, destination port number, length, and checksum. The checksum field offers an opportunity to discard packets that get damaged in transit. This field is optional and is rarely used because there i no mechanism in UDP to request a lost packet be resent. There is also no mechanism for sequencing data to reassemble it back into the original order. The payload of each received datagram is passed to the destination application without any processing.
The lack of connection procedures or data integrity checks makes UDP suitable for short request/response transactions, such as a DNS lookups and Network Time Protocol requests.
The short header of the UDP datagram creates a lot less overhead than the headers of TCP. That small administrative add-on can be reduced even further by setting the maximum datagram size to be much larger than the maximum IP packet size. In these instances, the large UDP datagram will be split up and carried by several IP packets. The UDP header is only included in the first of these packets, leaving the remaining packets with no overhead from UDP at all.
Although UDP has a total lack of administrative procedures, it is the preferred transport mechanism for real-time applications, such as video streaming or interactive voice transmissions. In these situations, though, UDP does not interact directly with the application. In the case of video streaming applications, the Real-time Streaming Protocol, the Real-time Transport Protocol, and the Real-time Control Protocol sit between UDP and the application to provide connection management and data shepherding functions.
Voice applications use the Session Initiation Protocol, the Stream Control Transmission Protocol, and the Real-time Transport Protocol to overlay UDP and provide the missing session management functions.
TCP/IP applications
The applications defined as protocols in the TCP/IP suite are not end-user functions, but network administration tools and services. Some of these applications, such as the File Transfer Protocol (FTP), define programs that can be accessed directly by the user.
Protocols resident in the Application Layer include HTTP and HTTPS, which manage the request and transfer of web pages. The email management protocols Internet Message Access Protocol (IMAP), the Post Office Protocol (POP3), and the Simple Mail Transfer Protocol (SMTP) are also categorized as TCP/IP applications.
As a network administrator, you would be interested in the DNS, DHCP, and SNMP applications. The Simple Network Management Protocol is a network messaging standard that is universally implemented in network equipment. Many network administration tools employ SNMP.
Domain Name System
The Domain Name System (DNS) translates web addresses to actual IP addresses for website access over the Internet. DNS is an essential service on private networks. It works together with the DHCP system and coordination provided by an IP Address Manager (IPAM) to form the network address monitoring tool group known as DDI (DNS/DHCP/IPAM).
Dynamic Host Configuration Protocol
Despite the fact that the pool of IPv4 addresses ran out in 2011, companies and individuals are still reluctant to switch over to IPv6. The introduction of IPv6 started in 2006. That means five years passed when everyone in the networking industry was aware of the end of IPv4 addressing but still did nothing to transition to the new system.
In 2016, IPv6 had passed 20 years since inception and ten years since commercial deployment, and yet less than 10 percent of the browsers in the world could load websites via an IPv6 address.
The reluctance to ditch IPv4 led to strategies to reduce address exhaustion. The main method to maximize the use of IP address pools is provided by DHCP. This methodology shares out a pool of addresses among a larger group of users. The fact that IP addresses only have to be unique on the internet at a particular moment in time enables ISPs to allocate addresses for the duration of user sessions. So, when one customer disconnects from the internet, that address immediately becomes available to another user.
DHCP has also become widely used on private networks because it creates an automatic IP address allocation method and cuts down the manual tasks that a network administrator has to perform in order to set up all of the endpoints on a large network.
Network Address Translation
Another TCP/IP application, Network Address Translation, has also helped reduce demand for IPv4 addresses. Rather than a company allocating a public IP address to each workstation, they now keep addresses on the network private.
The NAT gateway attaches port numbers to outgoing requests that leave the private network to travel over the internet. This enables large businesses to perform all of their external communications on the internet with just one IP address. When the response to the request arrives, the presence of the port number in the header enables the gateway to direct the packets to the originator of the request on the private network.
NAT gateways not only help to reduce the demand for IPv4 addresses but they also create a firewall because hackers cannot guess the private IP addresses of each endpoint behind the gateway. The proliferation of wifi routers for home use also helps reduce the demand for IPv4 addresses, because they use NAT to represent all of the devices on the property with one public IP address.
The Best TCP/IP tools
The biggest TCP/IP issue at the moment is the transition to IPv6 addresses on your network. If your company is unlikely to give you a budget specifically for this task, then you need to look for administration tools that have “dual stack” capabilities and transition planning features. You can alternatively opt for free tools to help transition all of your network addresses to IPv6.
Fortunately, all of the major DHCP and DNS server providers have been aware of the transition to IPv6 for at least a decade. Whichever provider you get your server software from, you can be sure that it is IPv6 compatible, so you won’t need to start again with those services.
The key pieces of equipment you need to focus on when transitioning to IPv6 are your network monitors and IP address managers.
You can employ three different strategies to bridge between IPv4 and IPv6 addressing. These five software packages give you the opportunity to implement your chosen approach. You can read about each of the strategies in the description of the tools below.
Our methodology for selecting a TCP/IP tool
We reviewed the market for network tools that manage TCP/IP systems and analyzed tools based on the following criteria:
- IP address management
- IP address tools for understanding address allocation
- Services to coordinate and support TCP/IP usage
- Methods to convert between IPv4 and IPv6
- Tracking coordination between DHCP and DNS
- A free trial for a no-cost assessment or a free tool
- A handy free utility or a paid tool that provides a good deal
With these selection criteria in mind, we have investigated a selection of log management tools that are suitable for businesses of all sizes.
1. Men & Mice IP Address Management
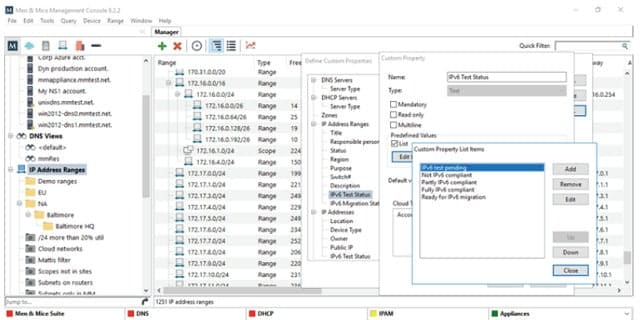
Men and Mice produces network management software, including a DDI package. Its IP Address Management tool is part of that suite. The company offers a limited version of its IP Address Management utility to implement a migration from IPv4 to IPv6 addresses. This reduced function version is free. If you buy the full IPAM, the migration systems are included. Men & Mice also offers a free trial for its DDI software suite.
Key Features
- A full DDI solution
- Clod based system
- Address transition support
- Free version available
Why do we recommend it?
Men & Mice IP Address Management is a straightforward cloud-based IPAM that can be integrated with your own local DHCP and DNS servers or you can use it alongside DNS and DHCP from Men & Mouse. A rival IPAM platform, called BlueCat, has recently taken over Men & Mice.
The address migration strategy outlined by Men and Mice introduces an extra field on your IPAM nodes report that notes the status of each device. With this you can record whether a device is IPv6 compatible. For those compatible devices, which will be most of your equipment, note whether the device has been tested with an IPv6 address and when it is ready for transfer.
The dashboard includes a workflow add-on, which tracks changes in the address format for each device. You can then switch devices either item by item, or subnet-wide. The compatibility of all addresses on a mid-transition network is supported by dual-stack architecture in the IPAM.
A free version of the IP Address Management system is a great opportunity. However, as it will only be capable of performing address transition and not fully managing your IP addressing system, you will end up running two IPAMs in parallel. It would be better to use the free trial as a parallel assessment of introducing a new IP Address Management system and perform the address standard transition during that trial. If you are happy with your current IPAM, then trying out the Men & Mice system for migrating your addresses would be a time-consuming exercise without the maximum benefit of acquiring new software.
Who is it recommended for?
Men & Mice offers a straightforward IP address manager but its Moustro package is much more interesting. This creates an overlay network, which manages IP addresses for multiple sites and cloud platforms as though they were a single network with one address space. That product will interest businesses with hybrid networks.
Pros:
- Offers DNS and DHCP monitoring and management for more centralized control of your networks
- Viable management solutions for MSPs
- Is able to track addressing issues in cloud and hybrid environments
- Browser-based dashboard makes the product more accessible than similar tools
Cons:
- The interface could be made more user-friendly and use more visualizations
- Integrations into some cloud providers can be time-consuming
2. IPv6 Tunnel Broker

The dual-stack method is just one of three possible transition strategies for IPv6 address transition. Another method is called “tunneling.” In this scenario, the packets addressed in one method are encapsulated in packets following the other addressing method. The most likely direction for this strategy is to put IPv6 packets inside IPv4 packets.
Key Features
- Performs live translation between IPv4 and IPv6 addresses
- Free to use
- Cloud-based service
Why do we recommend it?
The IPv6 Tunnel Broker from Hurricane Electric Internet Services is an interesting free service for mapping IPv6 addresses to IPv4 addresses. This is a way to deal with incompatible addresses in external connections. This is a transition strategy to deal with a world where both IPv4 and IPv6 addresses exist side by side.
Tunneling converts IPv6 addresses so that your IPv4 network can handle them. Once the encapsulated IPv6 packets arrive at the relevant device, the carrying structure is stripped off, so the requesting application can process the original IPv6 packet.
Tunneling is more of a delay strategy to put off transition and overcome any compatibility worries you may have. The tunneling method is outlined in a document held by the IETF. This is RFC 4213: Basic Transition Mechanisms for IPv6 Hosts and Routers. With this method, you can keep your network entirely IPv4 and communicate with IPv4 external resources in the standard way. All IPv6 addresses are converted to IPv4 so that your network gateway can deal with them. The intention is that you will switch the versions around at some point, making your network entirely IPv6 and tunneling in any external addresses that still use IPv4.
A good feature of this methodology is it can be implemented with a proxy server provided by third-parties, called tunnel brokers. IPv6 Tunnel Broker and Hurricane Electric are two of those conversion services. The companies have proxy servers in many cities in the USA and around the world. These tunnel brokers are completely free of charge.
Who is it recommended for?
The tunneling service is a short-term solution and performs a task that you could actually implement on your own router. For example, the system requires that you have an IPv6-enabled router in order to contact the tunneling service. However, you could tunnel those addresses yourself to pass traffic into your IPv4 network.
Pros:
- Completely free to use
- Is accessible from anywhere (simple web browser access)
- Offers robust documentation
Cons:
- Not the best option for larger environments
3. Cloudflare IPv6 Translation
The third recommended method for IPv4 to IPv6 transition is address conversion. Many Cloud services integrate IPv6 translation. Cloudflare is an example of this. The company principally offers protection against DDoS attacks. It acts as a front end to all of your incoming messages. When you sign up for the Cloudflare service, all of the DNS entries in the world that relate to your servers get altered to point to a Cloudflare server instead. Cloudflare scrubs out malicious connections and forwards the genuine traffic on to your servers.
Key Features
- Integrated into a package of edge services
- Translates between IPv4 and IPv6
- Free features in any Cloudflare service
Why do we recommend it?
Cloudflare IPv6 Translation is a cloud-based service. While it was still a startup, Cloudflare sought out products that would attract media attention and create brand recognition. One of those services was a standalone IPv6 Translation service. That product no longer exists, but Cloudflare provides an automatic translation option in all of its products.
The company’s Pseudo IPv4 function is included for free in all of its protection plans. It converts IPv6 addresses to IPv4 addresses before they arrive at your network gateway. This is a great solution if you have older equipment that can’t deal with IPv6 addresses. This should help squeeze out a little extra service life before you have to buy new network devices. As all network equipment providers now integrate dual stack architecture as standard, your IPv6 compatibility problems will disappear as you replace your equipment.
Who is it recommended for?
While you can’t get a standalone IPv6 translator for Cloudflare, you would get that service with any Cloudflare product, such as the Cloudflare DNS service and its DDoS protection system. Most of those services are free for small businesses. Larger businesses have to get a paid plan to provide suitable traffic throughput.
Pros:
- Offers numerous other services like DDoS protection
- Is a free feature
- Incredibly easy to use
Cons:
- Only available as a cloud-based tool
4. SolarWinds IP Address Manager
![]()
Key Features
- Scans the network for all devices
- Examines IP address allocations
- Spots rogue devices
- Updates DHCP address pool
- Checks on DNS records
Why do we recommend it?
SolarWinds IP Address Manager includes a DHCP server and a DNS server, making it a full DDI suite. However, you can choose to use the native DNS and DHCP servers that are built into Windows Server instead. This tool sweeps the network and records the IP addresses currently in use.
SolarWinds has made the IP Address Manager a “dual stack” system, which means it can work with IPv6 addresses as well as IPv4. The tool includes features to help you migrate your network addressing system from IPv4 to IPv6.
SolarWinds’ “dual IP stack” system makes each node on your network a potential IPv6/IPv4 node. You just have to set the configuration for each node in your dashboard. A node can be IPv4 only, IPv6 only, or both IPv4 and IPv6. So, when transitioning,
start off with IPv4 nodes. Set them all to IPv6/IPv6 nodes and reconfigure your DHCP and DNS servers to work with IPv6 addresses. Once that configuration has been shown to work effectively, simply switch off the IPv4 capabilities to make an IPv6 network. SolarWinds calls this the “dual stack transition method.”
The IPAM includes a planning tool to transition to IPv4. You can introduce new addresses subnet by subnet. The software handles IP address conflicts during transition. The scopes for subnetting are different to those available in IPv4, so the subnetting features of the SolarWinds IP Address Manager, which include a subnet calculator, will help keep track of the migration.
Once your new addressing system is in place, you won’t have to worry about compatibility between the two addressing systems because your entire network will be on the IPv6 format. The IP Address Manager continually scans your network for IP addresses and compares those to the allocations registered in your DHCP server. This enables the IPAM to detect abandoned addresses and return them to the pool. The periodic system checks help you detect rogue devices on the network, and you can also check for irregular activity that identifies intruders and viruses.
Who is it recommended for?
This service is easy to use and you don’t need strong technical skills to operate it. So, it is suitable for businesses of all sizes. However, small businesses could probably get away with using a free IP address scanner, so this package is aimed at mid-sized and large businesses.
Pros:
- Comprehensive DDI package, great for small and large networks
- Can track addressing issues such as IP conflicts, misconfigurations, and subnet capacity limitations
- Lightweight – runs on a simple Windows Server deployment
- Features subnet allocation tools to save tons of time on address allocation and planning
- Templated reports can easy to execute and customizable
Cons:
- Not designed for home users, this is an in-depth networking tool built for IT professionals
You can check out the IP Address Manager on a 30-day free trial. It can only be installed on Windows Server.
5. Subnet Online IPv4 to IPv6 Converter
The network address translation server is the obvious on-site location for dynamic address conversion. Most new NAT servers include conversion capabilities. In the network equipment manufacturer’s world, the process of converting addresses between IPv4 and IPv6 is called “protocol translation.”
Key Features
- Online subnet calculator
- Includes conversion calculator from IPv4 and IPv6
- Free to use
Why do we recommend it?
The Subnet Online IPv4 to IPv6 Converter is an essential tool for any network manager. It gives you three IPv6 options, which are regular IPv6 addresses, IPv6 condensed, and IPv6 alternative. The site also provides regular subnet calculators.
A fourth option exists, which is to manually change all of your addresses. This is a feasible strategy for small networks. If you use DHCP, you can set a dual-stack DHCP server to use IPv6 addressing. The same strategy is available with DNS servers. If you set your IPAM to only use IPv6, the presence of IPv4 on your network will end.
Changing over the addressing system will have an impact on your subnet address allocation. You can recalculate your subnet address scopes yourself. The Subnet Online IPv4 to IPv6 Converter will help you with that task.
With your own addresses converted, you need to rely on the conversion settings of your NAT gateway to adapt external IPv4 address and integrate them into your operations.
Who is it recommended for?
This is a free tool that can be accessed from anywhere through a standard Web browser. So, as long as you can access the internet, you can get this tool. The site also includes tutorials on IP address calculation, which are great for networking students or small businesses owners who are learning about network management as they go along.
Pros:
- Includes an online subnet calculator
- Can help you convert from IPv4 to IPv6
- Better suited for home labs and small networks
Cons:
- Lack features larger networks would look for such as address conversion
TCP/IP relevance
Despite being one of the oldest network management systems, TCP/IP isn’t about to age out. In fact, as time goes by, TCP/IP has grown to greater prominence in the field. The ability to interchange private networks with the internet gives TCP/IP an edge and has made it the most attractive solution for network systems. Once you understand how TCP/IP works, you can visualize how all of your company’s communications travel, and that makes expanding network services or resolving problems a lot easier.
TCP/IP future
The only rival to TCP/IP was OSI, and that model has embedded itself into the jargon of networking. It can be confusing that OSI layer numbers are used habitually even when referring to equipment that works along TCP/IP rules. This is a quirk of the industry that you will come to accept and use as a second language.
IPv4 address exhaustion is a strange upset in the trajectory of TCP/IP adoption. This glitch didn’t force network managers to switch to other methodologies. Instead, the necessity to make the most of the decreasing pool of available addresses spawned new technologies and strategies that maximized usage of IP addresses. The big problem created by the shortage of addresses led to the DHCP system, IPAMs, and more effective IP address management. All of which make TCP/IP a much more attractive network management system.
TCP/IP utilization
Many, many more protocols are involved in TCP/IP. However, this guide has focused on the most important methodologies you need to understand in order to effectively manage a network.
Remember that a protocol is not a piece of software. It is just a set of rules that software developers use as the basis of a program specification. The protocols ensure universal compatibility and enable different software houses to produce competing products that work with other software.
Have you converted your network to IPv6 yet? Has the new addressing system impacted connectivity? Did you use the dual-stack method in an IPAM to cover both IPv4 and IPv6 addresses simultaneously? Let us know your experience by leaving a message in the Comments section below.
TCP/IP FAQs
What are the 4 levels of TCP IP?
There are actually two layers in TCP/IP: the Internet Layer and the Transport Layer. In order to create an equivalence with the seven layers of the Open System Interconnection (OSI) protocol stack, many network teaching institutions have added a big block below the Internet Layer, which jacks up the two TCP/IP layers to the height of the corresponding OSI layers. As there is nothing above the Transport Layer to match the Presentation Layer and the Application Layer of OSI, you will now see a large Application Layer block drawn into the TCP/IP stack. Adding these two blocks for teaching purposes brings the total number of layers in the TCP/IP stack up to four.
What is the TCP IP in a nutshell?
TCP/IP is a protocol suite and it is now the dominant framework for expressing the procedures for establishing and maintaining connections over networks and across the internet. The framework contains many individual protocols, which each describe one aspect of network procedures. These protocols are grouped into two levels: The Internet Layer and the Transport Layer. The most important protocol in the Internet Layer is the Internet Protocol. This is where the “IP” of TCP/IP comes from. You will see many internet-related things that have the letters IP in them, for example, internet telephony is called VoIP, which stands for Voice over IP. The most important protocol in the Transport Layer is the Transmission Control Protocol, which is the TCP in TCP/IP and it explains procedures to forge, maintain, and end network connections.
What are three three main features of TCP?
The Transmission Control Protocol (TCP) is known for its three-way handshake. This is a method of establishing a connection. A connection is the key characteristic of TCP. The alternative protocol in the Transport Layer of TCP/IP is called the User Datagram Protocol (UDP), which does not establish a connection and so is known as a connectionless protocol. The TCP connection is begun with a SYN packet sent by the client to the server and this requests a connection. The server replies with a SYN+ACK package, which says “Yes, OK.” The client then replies with an ACK message, which says “Let’s do it.”
Images: European Network from PXHere. Public domain
TCP/IP Model by MichelBakni. Licensed under CC BY-SA 4.0
OSI and TCP by Marinanrtd2014. Licensed under CC BY-SA 4.0


Superb, and easy to understand. Thank you.